1、简述
大语言模型(LLM)的崛起正在重塑推荐系统的设计范式,推动其从传统的多阶段 “召回-排序” 流水线,向端到端的生成式框架演进。这一新范式将推荐任务统一建模为序列到序列(Seq2Seq)的生成问题,其核心是直接生成用户可能感兴趣的物品 ID 或其标识符,这一过程被称为 “生成式召回”(Generative Retrieval)。
该领域的发展呈现出以下几个关键趋势:
-
统一的端到端架构:生成式推荐致力于将传统推荐流程中的召回、排序等多个独立优化的阶段整合进一个单一模型中。例如,
OneRec框架通过统一的生成式建模,同时实现了物品检索与排序,简化了系统架构并实现了端到端的联合优化。Actions Speak Louder than Words等工作进一步探索了万亿级别参数的序列模型,展示了其在生成式推荐任务上的强大潜力。 -
稀疏与稠密表征的融合:如何有效结合物品ID的精确性(稀疏特征)和文本/图像的泛化能力(稠密语义特征)是推荐系统的一大挑战。
Sparse Meets Dense论文提出了一种级联式的稀疏-稠密表示方法,让模型在生成推荐时能同时利用两种特征的优势,既保证了推荐的准确性,又增强了模型的泛化和探索能力。 -
工业级规模化应用与挑战:生成式推荐不仅停留在学术研究层面,已在工业界得到大规模应用。美团提出的
MTGR框架便是一个典型的工业级生成式推荐系统。其相关实践不仅验证了该范式的有效性,也揭示了在真实业务场景中面临的“规模法则”(Scaling Law)挑战,为后续研究和应用提供了宝贵的经验。 -
向相关任务的范式迁移:生成式推荐的思想也被成功扩展到其他相关领域。例如,
OneSug框架将这种端到端的生成式方法应用于电商领域的查询词推荐(Query Suggestion)任务,证明了该范式的通用性和灵活性。
本文将介绍工业界中以 LLM 为基础的生成式推荐系统,探索和见证推荐技术全新的发展阶段。
2、Google:TIGER
TIGER,一种新型的基于生成式检索的推荐框架,其为每个物品分配语义 ID,并训练检索模型以预测特定用户可能交互的物品的语义 ID
这种生成式检索新范式为序列推荐系统带来了两项额外能力:(1)能够推荐新物品和低频物品,从而改善冷启动推荐;(2)能够通过可调节参数生成多样化推荐
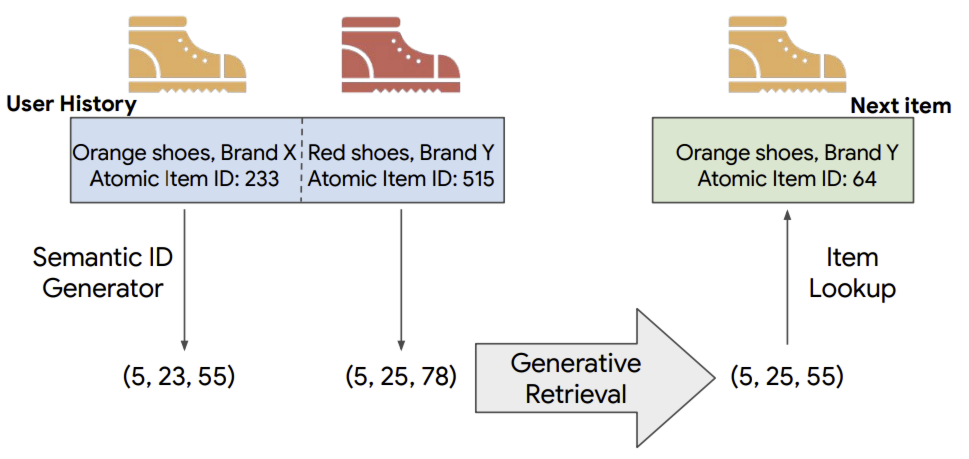
与传统的查询-候选匹配方法不同,Google 采用端到端生成式模型,直接预测候选 ID。即将 Transformer 的记忆(参数)用作推荐系统中检索的端到端索引,该方法称为 TIGER(Transformer Index for GEnerative Recommenders)。
TIGER 采用 “语义 ID(Semantic ID)” 的新型物品语义表示 —— 一种源自每个物品内容信息的标记序列。具体而言,给定物品的文本特征,使用预训练文本编码器(如 SentenceT5)生成密集的内容嵌入;然后对物品的嵌入应用量化方案,形成一组有序标记/码字,将其称为物品的语义 ID。最终,这些语义 ID 被用于在序列推荐任务上训练 Transformer 模型。
在语义上有意义的数据上训练 Transformer 记忆,能够实现相似物品间的知识共享。如此得以摒弃此前推荐模型中用作物品特征的原子化、随机的物品 ID。借助物品的语义标记表示,模型更不易受推荐系统中固有的反馈循环影响,从而能够泛化到语料库中新加入的物品。
此外,使用标记序列进行物品表示有助于缓解与物品语料库规模相关的挑战:可通过标记表示的物品数量是序列中每个标记基数的乘积。通常,物品语料库规模可达数十亿量级,为每个物品学习唯一嵌入会占用大量内存。虽然可采用基于随机哈希的技术来减小物品表示空间,但本研究表明,使用语义上有意义的标记进行物品表示是一种更具吸引力的替代方案。
2.1、框架
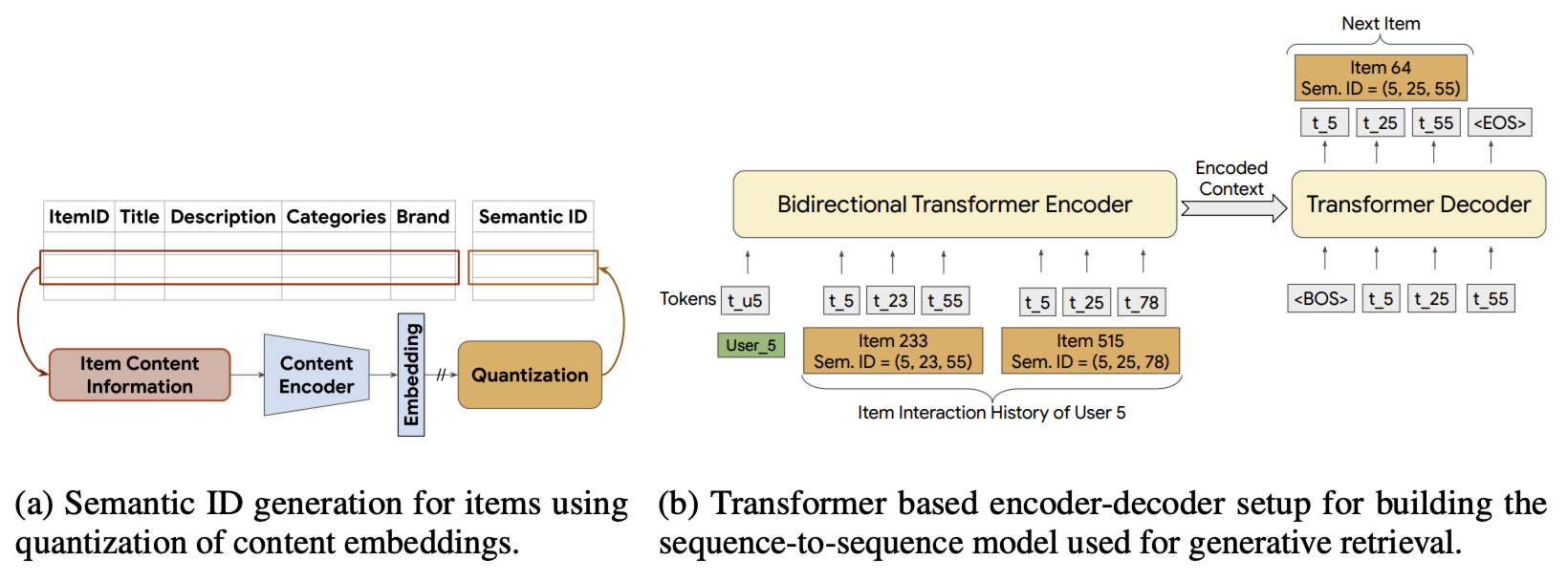
TIGER 包括两个阶段:
- 利用内容特征生成语义 ID。这包括将物品内容特征编码为嵌入向量,并将嵌入量化为语义码字元组。所得码字元组称为物品的语义 ID。
- 基于语义 ID 训练生成式推荐系统。使用语义 ID 序列在序列推荐任务上训练 Transformer 模型。
2.1.1、语义 ID 生成
假设每个物品都有关联的内容特征,这些特征包含有用的语义信息(如标题、描述或图像)。此外,假设可使用预训练的内容编码器生成语义嵌入 $\mathbf{x} \in \mathbb{R}^d$。例如,可使用 Sentence-T5、BERT 等通用预训练文本编码器,将物品的文本特征转换为语义嵌入。随后对语义嵌入进行量化,为每个物品生成语义 ID。
将语义 ID 定义为长度为 $m$ 的码字元组。元组中的每个码字来自不同的码本。因此,语义 ID 可唯一表示的物品数量等于各码本大小的乘积。尽管生成语义 ID 的不同技术会使 ID 具有不同的语义属性,但要求它们至少满足以下特性:相似物品(内容特征相似或语义嵌入接近的物品)应具有重叠的语义 ID。例如,语义 ID 为 (10, 21, 35) 的物品应比 ID 为 (10, 23, 32) 的物品更相似于 ID 为 (10, 21, 40) 的物品。
用于语义 ID 的 RQ-VAE:残差量化变分自编码器(RQ-VAE)是一种多级向量量化器,通过对残差进行量化生成码字元组(即语义 ID)。自编码器通过更新量化码本和 DNN 编码器-解码器参数进行联合训练。
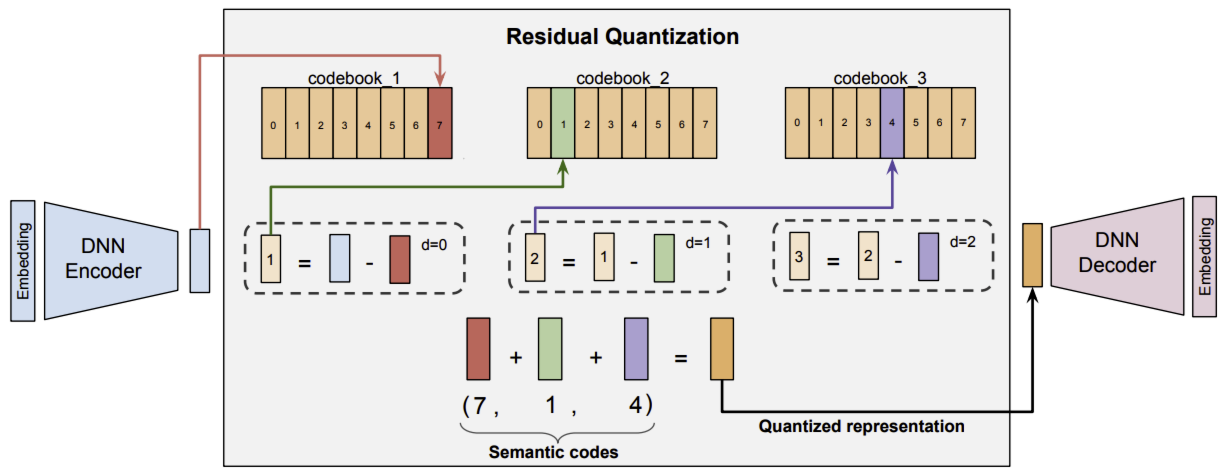
RQ-VAE 首先通过编码器 $\mathcal{E}$ 对输入 $x$ 进行编码,学习潜在表示 $z := \mathcal{E}(x)$。在第 0 级($d=0$),初始残差定义为 $r_0 := z$。在每一级 $d$,存在一个码本 \(\mathcal{C}_d := \{e_k\}_{k=1}^K\),其中 $K$ 为码本大小。然后,通过将 $r_0$ 映射到该级码本中最近的嵌入来对其进行量化。$d=0$ 时最接近嵌入 $e_{c_0}$ 的索引,即 \(c_0 = \arg\min_i \|r_0 - e_k\|\),表示第 0 个码字。对于下一级 $d=1$,残差定义为 $r_1 := r_0 - e_{c_0}$。与第 0 级类似,第 1 级的码字通过在第 1 级码本中找到与 $r_1$ 最接近的嵌入来计算。该过程递归重复 $m$ 次,得到表示语义 ID 的 $m$ 个码字元组。这种递归方法从粗到细地近似输入。
需要注意的是,$m$ 个级别各使用一个大小为 $K$ 的独立码本,而非单个大小为 $mK$ 的码本。这是因为残差的范数会随级别升高而减小,从而允许不同级别具有不同的粒度。
得到语义 ID $(c_0, \ldots, c_{m-1})$后,$z$ 的量化表示计算为 $\hat{z} := \sum_{d=0}^{m-1} e_{c_i}$。随后 $\hat{z}$ 被传入解码器,解码器尝试使用 $\hat{z}$ 重构输入 $x$。RQ-VAE 的损失定义为:
\[\mathcal{L}(x) := \mathcal{L}_{\text{recon}} + \mathcal{L}_{\text{rqvae}}\]其中:
\[\mathcal{L}_{\text{recon}} := \|x - \hat{x}\|^2\] \[\mathcal{L}_{\text{rqvae}} := \sum_{d=0}^{m-1} \|\text{sg}[r_i] - e_{c_i}\|^2 + \beta\|r_i - \text{sg}[e_{c_i}]\|^2\]这里 $\hat{x}$ 是解码器的输出,$\text{sg}$ 为停止梯度操作。该损失联合训练编码器、解码器和码本。
为防止 RQ-VAE 出现码本坍缩(即大部分输入映射到少数码本向量),采用基于 k-means 聚类的码本初始化方法。具体而言,对首个训练批次应用 k-means 算法,并将聚类中心用作初始化值。
其他量化方案:生成语义 ID 的一种简单替代方案是使用局部敏感哈希(LSH)。消融实验中发现,RQ-VAE 的性能确实优于 LSH。另一种选择是使用层次化 k-means 聚类,但它会丢失不同聚类之间的语义关联。此外 VQ-VAE 在检索过程中生成候选物品的性能与 RQ-VAE 相近,但它丢失了 ID 的层次结构。
冲突处理:根据语义嵌入的分布、码本大小的选择以及码字长度,可能会发生语义冲突(即多个物品映射到同一语义 ID)。为消除冲突,在有序语义编码的末尾附加一个额外标记,使其唯一。例如,若两个物品共享语义ID $(12, 24, 52)$,附加额外标记以区分它们,将两个物品表示为 $(12, 24, 52, 0)$ 和 $(12, 24, 52, 1)$。为检测冲突,维护一个将语义 ID 映射到对应物品的查找表。需要注意的是,冲突检测和修复仅在 RQ-VAE 模型训练完成后执行一次。此外,由于语义 ID 是整数元组,与高维嵌入相比,该查找表在存储方面更为高效。
2.1.2、基于语义 ID 的生成式检索
通过按时间顺序排序用户交互过的物品,为每个用户构建物品序列。对于形如 \((\text{item}_1, \ldots, \text{item}_n)\) 的序列,推荐系统的任务是预测下一个物品 \(\text{item}_{n+1}\)。
形式上,设 \((\text{c}_{i,0}, \ldots, \text{c}_{i,m-1})\) 为物品 \(\text{item}_i\) 的 $m$ 长度语义 ID。将物品序列转换为 \((\text{c}_1,_0, \ldots, \text{c}_1,_{m-1}, \text{c}_2,_0, \ldots, \text{c}_2,_{m-1}, \ldots, \text{c}_n,_0, \ldots, \text{c}_n,_{m-1})\) 序列。然后训练序列到序列模型,以预测物品 \(\text{item}_{n+1}\) 的语义 ID \((\text{c}_{n+1},_0, \ldots, \text{c}_{n+1},_{m-1})\)。
由于框架具有生成式特性,解码器生成的语义 ID 可能与推荐语料库中的物品不匹配,但此类事件发生的概率较低。
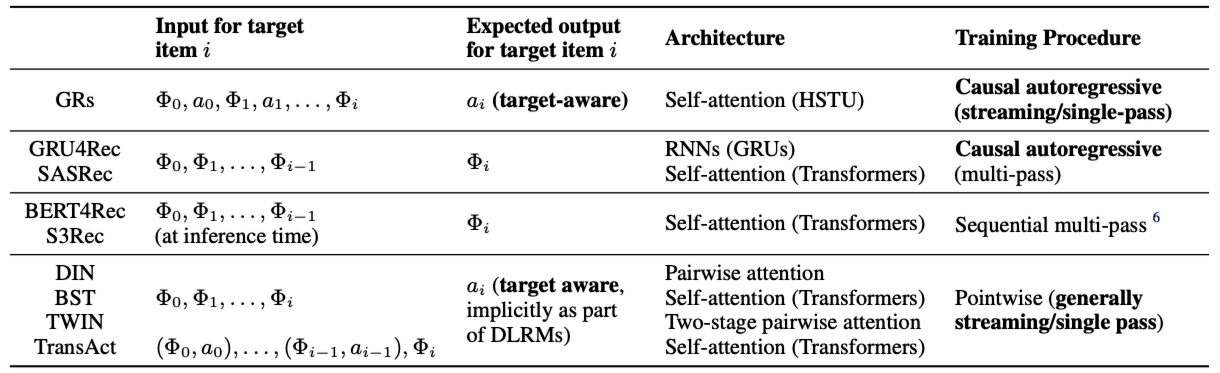
3、Meta:GRs 和 HSTU
Meta 将推荐问题重新表述为生成建模框架内的序列转导任务(sequential transduction tasks)。这一新范式使得推荐问题可以在生成模式下进行训练,从而允许在相同计算量下处理更多的数据。
为了解决生成式推荐训练和推理过程中的计算成本挑战,HSTU(Hierarchical Sequential Transduction Units) 针对大型非静态词汇表改进了注意力机制,并利用推荐数据集的特性,在长度为 8192 的序列上,相比基于 FlashAttention2 的 Transformer 实现了 5.3 倍至 15.2 倍的速度提升。
此外,M-FALCON 算法通过微批处理完全分摊计算成本,能够在与传统 DLRMs(Deep Learning Recommendation Models) 相同的推理预算下,服务复杂程度高 285 倍的 GR(Generative Recommenders) 模型,同时实现 1.50 倍至 2.99 倍的速度提升。
3.1、从 DLRMs 到 GRs
3.1.1、统一 DLRMs 中的异质特征空间
现代 DLRM 模型通常使用大量分类(“稀疏”)特征和数值(“稠密”)特征进行训练。GRs 将这些特征整合并编码为单一的统一时间序列。
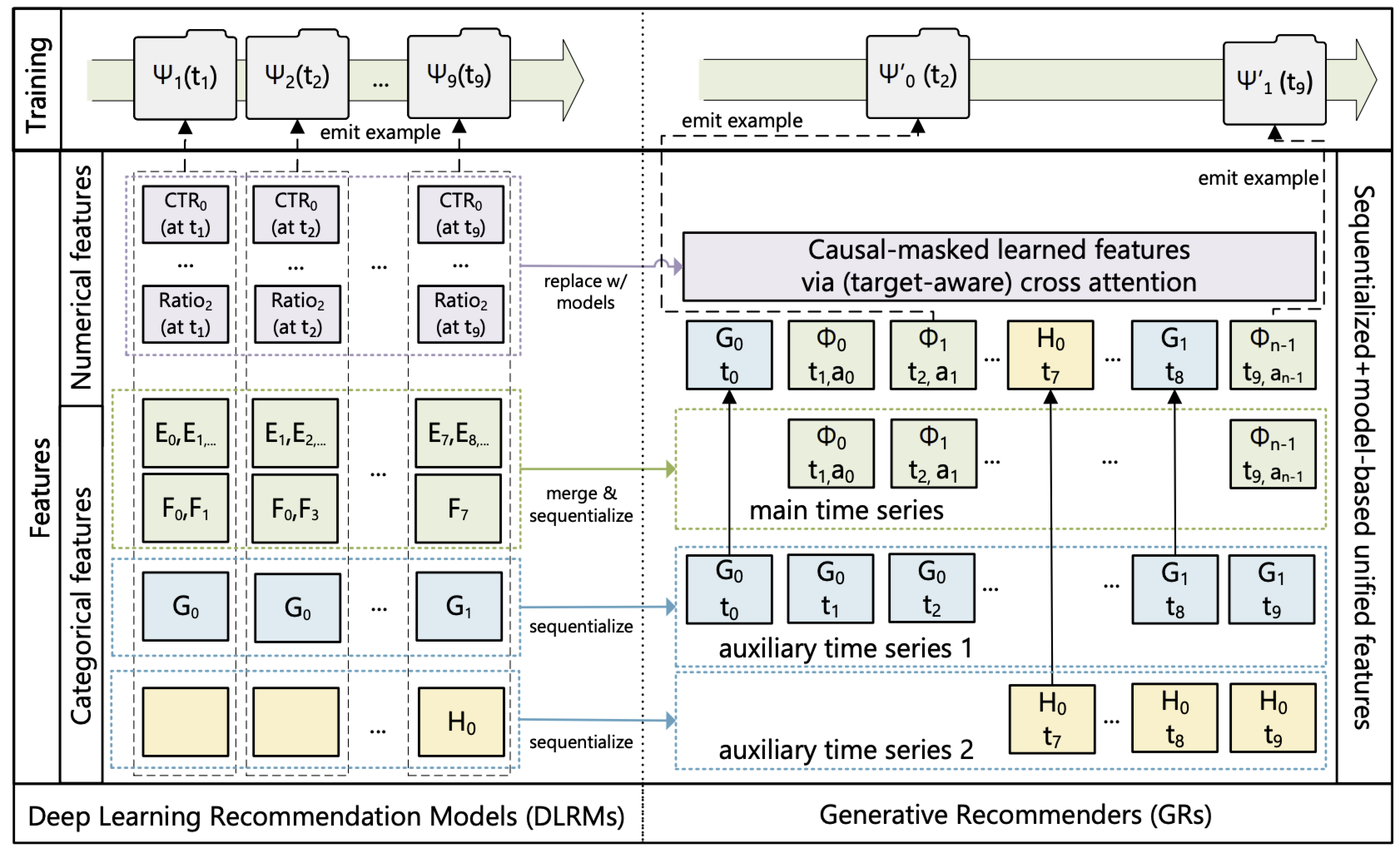
分类(“稀疏”)特征:这类特征包括用户喜欢的物品、用户关注的某类别(如“户外”)创作者、用户使用的语言、用户加入的社区、请求发起的城市等。
采用如下方式将这些特征序列化:首先选择最长的时间序列作为主时间序列,这通常是通过合并代表用户互动过的物品的特征得到的。其余特征通常是随时间缓慢变化的时间序列,如人口统计特征或关注的创作者。通过保留每个连续段的最早条目来压缩这些时间序列,然后将结果合并到主时间序列中。由于这些时间序列变化非常缓慢,这种方法不会显著增加整体序列长度。
数值(“稠密”)特征:这类特征包括加权衰减计数器、比率等。例如,某个特征可能代表用户在与特定主题匹配的物品上的历史点击率(CTR)。与分类特征相比,这些特征变化频繁得多,可能每一次(用户,物品)交互都会变化。因此,从计算和存储角度来看,完全序列化这类特征是不可行的。然而,我们进行聚合所依据的分类特征(如物品主题、位置)在 GRs 中已经被序列化和编码。因此,在 GRs 中,只要有足够表达能力的序列转导架构,结合目标感知公式,随着 GRs 中整体序列长度和计算量的增加,就能有意义地捕捉到数值特征,因此可以在 GRs 中移除数值特征。
3.1.2、将排序和检索重构为序列转导任务(sequential transduction tasks)
给定 $n$ 个标记的列表 $x_0, x_1, \ldots, x_{n-1}$($x_i \in X$)(按时间顺序排列),以及标记被观察到的时间 $t_0, t_1, \ldots, t_{n-1}$,序列转导任务会将这一输入序列映射到输出标记 $y_0, y_1, \ldots, y_{n-1}$(\(y_i \in X \cup \{\emptyset\}\)),其中 $y_i = \emptyset$ 表示 $y_i$ 未定义。
用 $\Phi_i \in X_c$($X_c \subseteq X$)表示系统向用户提供的内容(例如图像或视频)。由于新内容不断产生,$X_c$ 和 $X$ 都是非平稳的。用户可以通过某些动作 $a_i$(例如点赞、跳过、视频完成+分享)对 $\Phi_i$ 做出响应,其中 $a_i \in X$。用$n_c$表示用户交互过的内容总数。
在因果自回归场景下,标准的排序和检索任务可被定义为序列转导任务。

检索:在推荐系统的检索阶段,学习 $\Phi_{i+1} \in X_c$ 上的分布 $p(\Phi_{i+1} \mid u_i)$,其中 $u_i$ 是标记 $i$ 处的用户表示。一个典型目标是选择 $\arg\max_{\Phi \in X_c} p(\Phi \mid u_i)$ 以最大化某种奖励。
这在两个方面不同于标准的自回归设置。第一,$x_i$、$y_i$ 的监督信号不一定是 $\Phi_{i+1}$,因为用户可能对 $\Phi_{i+1}$ 做出负面响应。第二,当 $x_{i+1}$ 表示与交互无关的分类特征(如人口统计学特征)时,$y_i$ 是未定义的。
排序:GR 中的排序任务面临独特挑战,因为工业级推荐系统通常需要 “目标感知” 的形式。在这类场景中,目标 $\Phi_{i+1}$ 与历史特征的 “交互” 需要尽早发生,而这在标准自回归设置中无法实现 —— 在标准设置中,“交互” 发生较晚(例如,在编码器输出后通过softmax实现)。
可以通过物品与动作的交错排列解决这一问题,排序任务可以表示为 $p(a_{i+1} \mid \Phi_0, a_0, \Phi_1, a_1, \ldots, \Phi_{i+1})$(在分类特征之前)。在实际应用中,使用一个小型神经网络将 $\Phi_{i+1}$ 处的输出转换为多任务预测。重要的是,这使得能够在一次处理中对所有 $n_c$ 次交互应用目标感知交叉注意力。
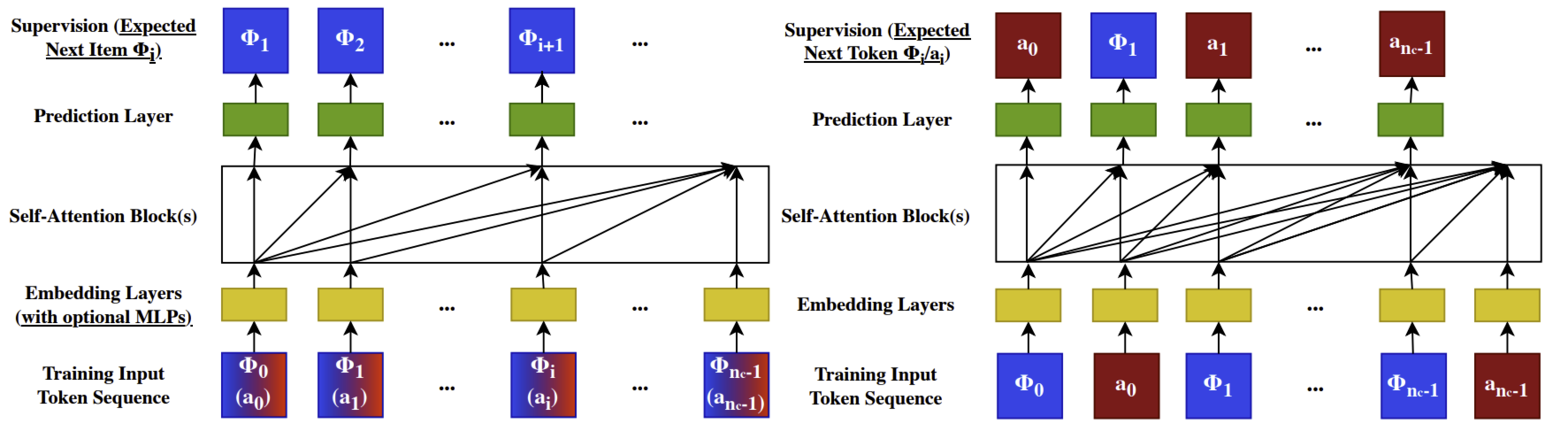
如下讨论传统序列推荐模型和深度学习推荐模型(DLRM)存在的三个局限性,以及生成式推荐模型(GRs)如何从问题范式的角度解决这些问题。
- 对用户交互物品之外特征的忽略:以往的序列模型范式仅考虑用户明确交互过的内容(物品),而生成式推荐模型出现之前的工业级推荐系统会基于大量特征进行训练,以增强用户和内容的表征。生成式推荐模型通过以下方式解决这一局限:
- 压缩其他分类特征并将其与主序列合并
- 利用目标感知范式(target-aware),通过交叉注意力交互捕捉数值特征。传统的 “仅考虑交互”(interaction-only) 的范式因忽略此类特征,导致模型性能显著下降;GR 模型仅在有交互的正样本上学习,会使 HitRate@100 下降 1.3%,NE 下降 2.6%。
- 用户表征在与目标无关的场景下计算:第二个问题是,大多数传统序列推荐模型,均采用与目标无关的范式 —— 对于目标物品 $\Phi_i$,模型将 $\Phi_0, \Phi_1, \ldots, \Phi_{i-1}$ 作为编码器输入来计算用户表征,再基于此进行预测。相比之下,工业场景中使用的大多数主流深度学习推荐模型,其序列模块采用目标感知的范式,能够将 “目标(排序候选)” 信息融入用户表征。这类模型包括 DIN、BST、TWIN 和 TransAct。GRs 融合了上述两种方法的优势,通过将内容序列与动作序列交织,实现了在因果自回归场景中应用目标感知注意力机制(target-aware attention)。
判别式限制了以往序列推荐模型在 pointwise 场景中的适用性,传统序列推荐模型在设计上具有判别性。现有序列推荐研究均对 $p(\Phi_i \mid \Phi_0, a_0, \ldots, \Phi_{i-1}, a_{i-1})$ 进行建模,即给定用户当前状态下,待推荐下一个物品的条件分布。另一方面,Meta 发现标准推荐系统中存在两个概率过程:
- 一是推荐系统向用户推送某一内容 $\Phi_i$(例如某张照片或某个视频)的过程;
- 二是用户通过某种行为 $a_i$(可能是点赞、看完视频、跳过等行为的组合)对所推送内容 $\Phi_i$ 做出反应的过程。
生成式方法需要对所推送内容序列和用户行为序列的联合分布(即 $p(\Phi_0, a_0, \Phi_1, a_1, \ldots, \Phi_{nc-1}, a_{nc-1})$)进行建模。Meta 的 GRs 能够对此类分布进行建模。需要注意的是,下一个行为标记($a_i$)的预测任务恰好对应生成式推荐模型的排序场景;而下一个内容($\Phi_i$)的预测任务则类似于适配于交织场景的检索场景,只是为了学习输入数据分布而改变了目标。
重要的是,这种范式不仅能够对数据分布进行合理建模,还能进一步通过波束搜索等方法直接采样待推荐给用户的物品序列。Meta 推测,与传统的列表式场景(例如 DPP 和 RL)相比,这种方法会更具优势。
3.1.3、生成式训练
工业级推荐系统通常在流式设置中进行训练,即每个样本在可用时被依次处理。在这种设置下,基于自注意力的序列转导架构(如 Transformer)的总计算需求随 $\sum_i n_i(n_i^2 d + n_i d f_{ff} d)$ 增长,其中 $n_i$ 是用户 $i$ 的标记数量,$d$ 是嵌入维度。括号中的第一部分来自自注意力,其缩放因子假设为 $O(n^2)$,这是因为大多数亚二次算法存在性能权衡问题,且在实际运行时间上表现不如二次算法。第二部分来自逐点 MLP 层,其隐藏层大小为 $O(f_{ff}) = O(d)$。若令 $N = \max_i n_i$,则整体时间复杂度简化为 $O(N^3 d + N^2 d^2)$,这在推荐场景中成本过高,难以承受。
为解决长序列上序列转导模型的可扩展训练难题,Meta 从传统的曝光级训练转向生成式训练,将计算复杂度降低 $O(N)$ 倍。通过这种方式,编码器成本可在多个目标间分摊。具体而言,当以速率 $s_u(n_i)$ 对第 $i$ 个用户进行采样时,总训练成本变为随 $\sum_i s_u(n_i) n_i(n_i^2 d + n_i d^2)$ 增长;若将 $s_u(n_i)$ 设为 $1/n_i$,则复杂度可简化为 $O(N^2 d + N d^2)$。在工业级系统中实现这种采样的一种方式是在用户请求或会话结束时生成训练样本,从而使 $\hat{s}_u(n_i) \propto 1/n_i$。
3.2、用于生成式推荐的高性能自注意力编码器
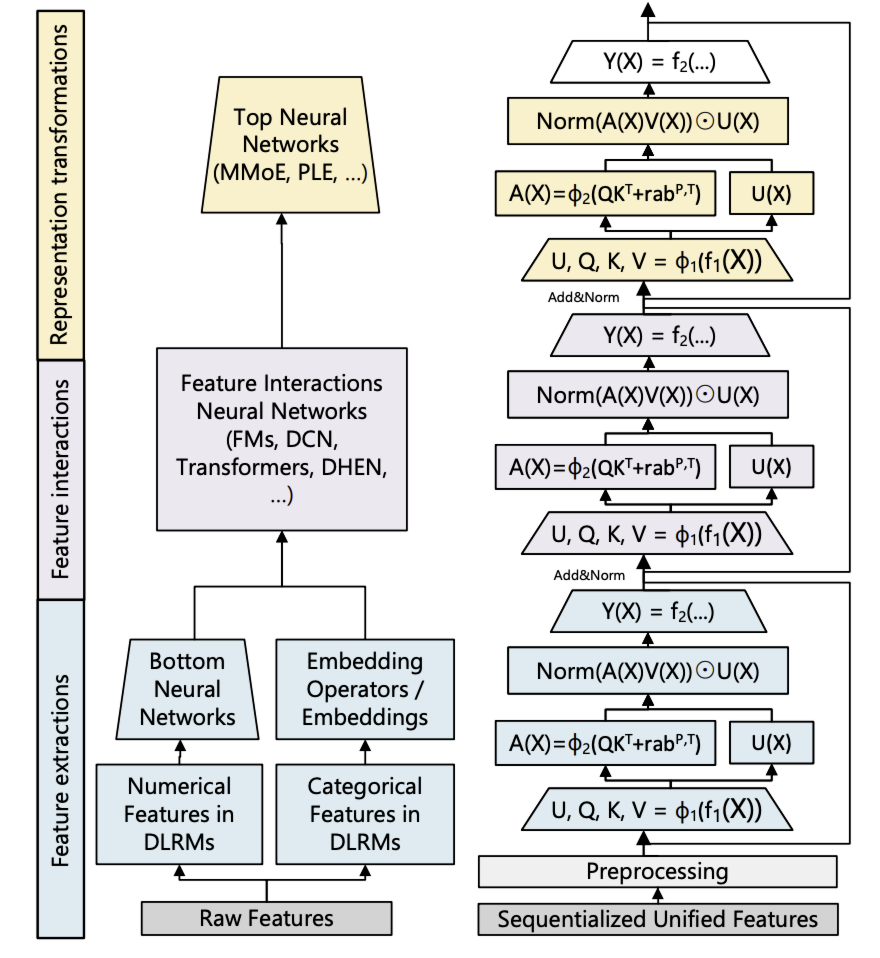
为了将生成式推荐(GRs)扩展到具有大型、非平稳词汇表的工业级推荐系统,HSTU(Hierarchical Sequential Transduction Unit,HSTU),一种新的编码器为此而设计。HSTU 由多个相同的层堆叠而成,层间通过残差连接相连。每层包含三个子层:逐点投影(公式1)、空间聚合(公式2)和逐点变换(公式3):
\[U(X), V(X), Q(X), K(X) = \text{Split}(\phi_1(f_1(X))) \tag{1}\] \[A(X)V(X) = \phi_2\left(Q(X)K(X)^T + \text{rab}^{p,t}\right)V(X) \tag{2}\] \[Y(X) = f_2\left(\text{Norm}(A(X)V(X)) \odot U(X)\right) \tag{3}\]其中,$f_i(X)$ 表示多层感知机(MLP);为降低计算复杂度,对 $f_1$ 和 $f_2$ 采用单层线性网络,即 $f_i(X) = W_i(X) + b_i$,并通过融合核对查询 $Q(X)$、键 $K(X)$、值 $V(X)$ 和门控权重 $U(X)$ 的计算进行批处理;$\phi_1$ 和 $\phi_2$ 表示非线性函数,两者均采用 SiLU;$\text{Norm}$ 表示层归一化;$\text{rab}^{p,t}$ 表示相对注意力偏置,其融合了位置(p)和时间(t)信息。
HSTU 编码器设计能够用单个模块化块替代深度推荐模型(DLRMs)中的异构模块。
DLRMs 实际上包含三个主要阶段:特征提取、特征交互和表示变换。特征提取用于获取分类特征的池化嵌入表示。其最先进的版本可概括为 pairwise 注意力和目标感知池化,而这一点可通过 HSTU 层实现。
特征交互是 DLRMs 中最关键的部分。常用方法包括因子分解机及其神经网络变体、高阶特征交互等。HSTU 通过让注意力池化特征借助 $\text{Norm}(A(X)V(X)) \odot U(X)$ 与其他特征直接 “交互”,从而替代了特征交互过程。这种设计的动机是,通过学习到的多层感知机(MLP)近似点积存在困难。由于对 $U(X)$ 应用了 SiLU,$\text{Norm}(A(X)V(X)) \odot U(X)$ 也可解释为 SwiGLU 的一种变体。
表示变换通常通过专家混合模型(MoEs)和路由实现,以处理多样、异构的群体。其核心思想是通过为不同用户专门设计子网络来执行条件计算。HSTU 中的逐元素点积在归一化因子范围内,实际上能够实现 MoEs 中使用的门控操作。
3.2.1、Pointwise aggregated attention
HSTU 采用了一种新的逐点聚合(归一化)注意力机制(相比之下,softmax 注意力会在整个序列上计算归一化因子)。这一设计基于两方面考量:首先,与目标相关的历史数据点数量是指示用户偏好强度的重要特征,而 softmax 归一化后难以捕捉这一信息 —— 这一点至关重要,因为我们既需要预测交互强度(例如,在某物品上的停留时间),也需要预测物品的相对排序(例如,预测能最大化 AUC 的排序)。其次,尽管 softmax 激活在设计上对噪声具有鲁棒性,但它在流式场景中对非平稳词汇表的适应性较差。
逐点聚合注意力机制如公式(2)所示。重要的是,逐点池化后需要进行层归一化以稳定训练。理解这一设计的一种方式是通过合成数据:遵循狄利克雷过程(Dirichlet Process)的合成数据会在非平稳词汇表上生成流式数据。在这种场景下,softmax 注意力与逐点注意力设置之间的性能差距可达 44.7%。
3.2.2、利用并通过算法增加稀疏性
在推荐系统中,用户历史序列的长度通常遵循偏斜分布,这导致输入序列具有稀疏性,尤其在序列极长的场景中。这种稀疏性可被利用以显著提升编码器效率。为此,Meta 为 GPU 开发了一种高效注意力核,通过融合连续的 GEMM(广义矩阵乘法)操作实现(类似 Rabe & Staats),但支持完全不规则的注意力计算。这实际上将注意力计算转化为多种尺寸的分组 GEMM。因此,HSTU 中的自注意力受内存限制,其内存访问量的复杂度为 $\Theta(\sum_i n_i^2 d_{\text{qk}} R^{-1})$,其中 $n_i$ 是样本 $i$ 的序列长度,$d_{\text{qk}}$ 是注意力维度,$R$ 是寄存器大小。这种方法本身可带来 2-5 倍的吞吐量提升。
Meta 通过 “随机长度(Stochastic Length,SL)” 进一步从算法层面增加用户历史序列的稀疏性。推荐场景中用户历史序列的一个关键特征是:用户行为具有时间重复性 —— 在整个交互历史中,用户行为会在多个尺度上体现。这为人工增加稀疏性提供了机会,且不会损害模型性能,从而显著降低与 $\Theta(\sum_i n_i^2)$ 成比例的编码器成本。
用户 $j$ 的历史可表示为序列 \((x_i)_{i=0}^{n_{c,j}}\),其中 $n_{c,j}$ 是该用户交互过的内容数量。令 \(N_c = \max_j n_{c,j}$,令 $(x_{i_k})_{k=0}^L\) 为由原始序列 \((x_i)_{i=0}^{n_{c,j}}\) 构造的长度为 $L$ 的子序列。SL 对输入序列的选择规则如下:
\[\begin{cases} (x_i)_{i=0}^{n_{c,j}} & \text{若 } n_{c,j} \leq N_c^{\alpha/2} \\ (x_{i_k})_{k=0}^{N_c^{\alpha/2}} & \text{若 } n_{c,j} > N_c^{\alpha/2} \text{,且概率为 } 1 - N_c^\alpha / n_{c,j}^2 \\ (x_i)_{i=0}^{n_{c,j}} & \text{若 } n_{c,j} > N_c^{\alpha/2} \text{,且概率为 } N_c^\alpha / n_{c,j}^2 \end{cases} \tag{4}\]这将注意力相关的复杂度降至 $O(N_c^\alpha d) = O(N^\alpha d)$,其中 $\alpha \in (1, 2]$。需要说明的是,将 SL 应用于训练可实现高性价比的系统设计,因为训练的计算成本通常远高于推理。
3.2.3、最小化激活内存使用量
在推荐系统中,使用大批次大小对训练吞吐量和模型性能都至关重要。因此,激活内存使用量成为主要的扩展瓶颈 —— 这与大型语言模型不同,后者通常使用小批次训练,且内存使用以参数内存为主。
与 Transformer 相比,HSTU 采用简化且完全融合的设计,显著减少了激活内存使用量。首先,HSTU 将注意力之外的线性层数量从 6 层减至 2 层,这与近期使用逐元素门控减少 MLP 计算的研究一致。其次,HSTU 将计算密集地融合为单个算子,包括公式(1)中的 $\phi_1(f_1(\cdot))$,以及公式(3)中的层归一化、可选的 dropout 和输出 MLP。这种简化设计使 bfloat16 精度下每层的激活内存使用量降至 $2d + 2d + 4h d_{\text{qk}} + 4h d_v + 2h d_v = 14d$。
作为对比,Transformer 在注意力后使用前馈层和 dropout(中间状态为 $3h d_v$),随后是逐点前馈块(包含层归一化、线性层、激活函数、线性层和 dropout),其中间状态为 $2d + 4d_{\text{ff}} + 2d + 1d = 4d + 4d_{\text{ff}}$。这里采用标准假设:$h d_v \geq d$ 且 $d_{\text{ff}} = 4d$。因此,算上输入和输入层归一化($4d$)以及 qkv 投影后,总激活状态为 $33d$。因此,HSTU 的设计支持将层数扩展至原来的 2 倍以上。
此外,用于表示词汇表的大规模原子 ID 也需要大量内存。对于 100 亿词汇表、512 维嵌入和 Adam 优化器,以 fp32 精度存储嵌入和优化器状态已需要 60TB 内存。为缓解内存压力,采用行级 AdamW 优化器,并将优化器状态存储在 DRAM 中,这将每个浮点数的 HBM(高带宽内存)使用量从 12 字节降至 2 字节。
3.2.4、通过成本分摊扩展推理
Meta 解决的最后一个挑战是推荐系统在服务时需要处理的大量候选物品。重点关注排序任务:对于检索任务,编码器成本可完全分摊,且已有高效算法适用于基于量化、哈希或分区的 MIPS(最大内积搜索),以及通过 beam search 或分层检索的非 MIPS 场景。
对于排序任务,候选物品数量可达数万个。Meta 提出了 M-FALCON(Microbatched-Fast Attention Leveraging Cacheable OperatioNs)算法,用于处理输入序列长度为 $n$ 的 $m$ 个候选物品的推理。在前向传播中,M-FALCON 通过修改注意力掩码和 $rab_{p,t}$ 偏置,使 $b_m$个 候选物品并行处理,且为这些候选物品执行的注意力操作完全相同。这将交叉注意力的成本从 $O(b_m n^2 d)$ 降至 $O((n + b_m)^2 d) = O(n^2 d)$(当 $b_m$ 相对于 $n$ 可视为小常数时)。可将全部 $m$ 个候选物品划分为 $\lceil m / b_m \rceil$ 个大小为 $b_m$ 的微批,以利用编码器级别的 KV 缓存 —— 要么跨前向传播降低成本,要么跨请求最小化尾部延迟。
总体而言,M-FALCON 使模型复杂度能随传统 DLRM 排序阶段的候选物品数量线性扩展;Meta 成功应用了复杂度高 285 倍的目标感知交叉注意力模型,且在推理预算固定的情况下,吞吐量提升了 1.5-3 倍。
问题:在推荐排序任务中,需要为用户的历史行为序列(长度为 $2n_c$)和每一个候选物品(例如有 $b_m$ 个)计算一个分数。传统方法是循环 $b_m$ 次,每次将一个候选物品拼接到历史序列后面,进行一次完整的模型推理。这种方式效率低下。
解决方案:M-FALCON 提出将 $b_m$ 个候选物品一次性全部拼接到用户历史序列的末尾,形成一个长度为 $(2n_c + b_m)$ 的长序列,然后只进行一次模型前向传播。
关键技术:修改注意力掩码(Attention Mask)
直接使用标准的因果自回归注意力掩码(causal mask)是行不通的,因为那样会导致后面的候选物品关注到前面的候选物品(例如,第2个候选物品会关注到第1个候选物品),从而影响各自打分的独立性。
M-FALCON 的巧妙之处在于修改了这个掩码。它确保:
历史序列部分:保持标准的因果注意力,即每个历史行为只能关注它之前的行为。
候选物品部分:
任何一个候选物品都可以关注所有的历史行为序列。
任何一个候选物品都不能关注和它在同一批次里的其他任何候选物品。这通过将候选物品之间的注意力权重设置为 $-\infty$ 来实现。
效果:通过这种特殊的注意力掩码,模型在一次前向传播中,为每个候选物品计算出的结果,与单独为它进行一次推理得到的结果是完全等价的。这相当于并行处理了 $b_m$ 个候选物品的打分过程,同时复用了对用户历史行为序列的编码计算,极大地提升了推理效率。
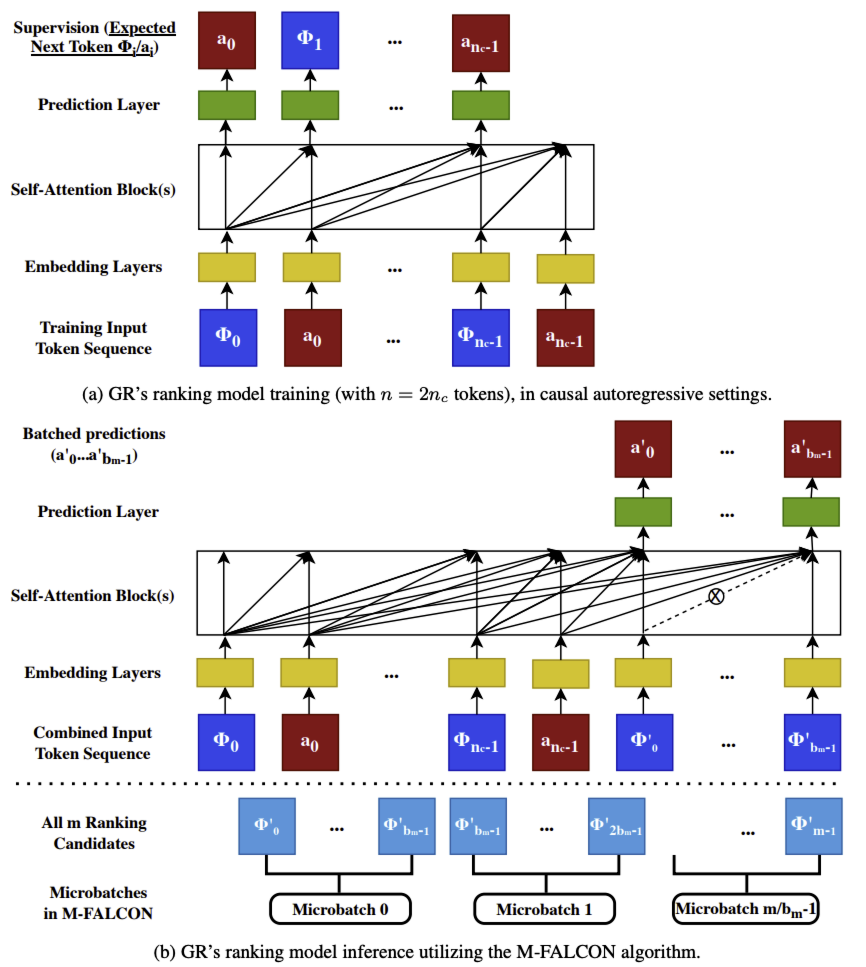
M-FALCON 引入了三个关键思想:
批量推理可应用于因果自回归场景。GR 中的排序任务采用目标感知方式构建。普遍观点认为,在目标感知场景中,需逐个对物品进行推理,对于 $m$ 个候选物品和长度为 $n$ 的序列,其成本为 $O(mn^2d)$。但本文将证明,这并非最优方案;即便是普通 Transformer,也可通过修改自注意力中使用的注意力掩码,对这类操作进行批量处理(“批量推理”),将成本降至 $O((n + m)^2d) = O(n^2d)$。
上图(a)和(b)均涉及因果自回归场景的注意力掩码矩阵。核心差异在于:图(a)在因果训练中使用大小为 $2n_c$ 的标准下三角矩阵;而图(b)通过将 $i、j \geq 2n_c$ 且 $i \neq j$ 的( $i, j$ )位置元素设为 False 或 $-\infty$,修改了大小为 $2n_c + b_m$ 的下三角矩阵,以防止目标位置 \(\Phi^{'}_{0}, \ldots, \Phi^{'}_{b_m-1}\) 之间相互注意力。不难发现,通过这种方式,\(\Phi^{'}_{i}、a^{'}_{i}\) 对应的自注意力模块输出仅依赖于 $\Phi_0, a_0, \ldots, \Phi_{n_c-1}, a_{n_c-1}$ ,而与 $\Phi’_j$ ( $i \neq j$ )无关。换言之,使用修改后的注意力掩码对 $(2n_c + b_m)$ 个标记进行一次前向传播,得到的最后 $b_m$ 个标记的结果,与对 $(2n_c + 1)$ 个标记进行 $b_m$ 次单独前向传播的结果一致 —— 其中,在第 $i$ 次前向传播中, $\Phi’_i$ 被置于第 $2n_c$ 位(0 基索引),并使用标准因果注意力掩码。
微批量将批量推理扩展至大规模候选集。排序阶段可能需要处理大量排序候选物品,数量可达数万个。我们可将全部 $m$ 个候选物品划分为 $\lceil m/b_m \rceil$ 个大小为 $b_m$ 的微批量,使得 $O(b_m) = O(n)$。在大多数实际推荐场景中(候选物品数量达数万个),这能保持前文所述的 $O((n + m)^2d) = O(n^2d)$ 运行时间。
编码器级缓存支持请求内和请求间的计算共享。最后,键值缓存(KV caching)可同时应用于请求内和请求间。例如,对于本文提出的 HSTU 模型,$K(X)$ 和 $V(X)$ 在微批量内和/或请求间完全可缓存。对于缓存的前向传播,仅需计算最后 $b_m$ 个标记的 $U(X)$ 、 $Q(X)$ 、 $K(X)$ 和 $V(X)$ ,同时复用包含 $n$ 个标记的序列化用户历史的缓存 $K(X)$ 和 $V(X)$ 。类似地, $f_2(\text{Norm}(A(X)V(X)) \odot U(X))$ 也仅需为 $b_m$ 个候选物品重新计算。这将缓存前向传播的计算复杂度降至 $O(b_m d^2 + b_m n d)$ ,即便在 $b_m = n$ 时,也比 $O((n + b_m)d^2 + (n + b_m)^2d)$ 的复杂度提升 2-4 倍。
4、字节跳动:HLLM
HLLM (Hierarchical Large Language Model) 采用两阶段的分层 LLM 结构:
物品 LLM (Item LLM):作为特征提取器,接收物品的详细文本描述,并将其转换为一个简洁、固定的高维嵌入向量。如此极大地缩短了输入序列的长度,使其与传统的 ID 推荐模型相当,从而降低了计算成本
用户 LLM (User LLM):作为用户兴趣模型,接收由物品 LLM 生成的物品嵌入序列(即用户的历史行为序列),并基于此序列进行学习,以预测用户的下一个行为
序列推荐任务的范式可定义为:给定用户 $u \in U$,以及用户 $u$ 按时间顺序排列的历史交互序列 $U = {I_1, I_2, \ldots, I_n}$,预测下一个物品 $I_{n+1}$,其中 $n$ 是序列 $U$ 的长度, $I \in \mathcal{I}$。每个物品 $I$都有对应的 ID 和文本信息(如标题、标签等),HLLM 提出的方法仅使用文本信息。
4.1、层次化大型语言模型架构 (Hierarchical Large Language Model)
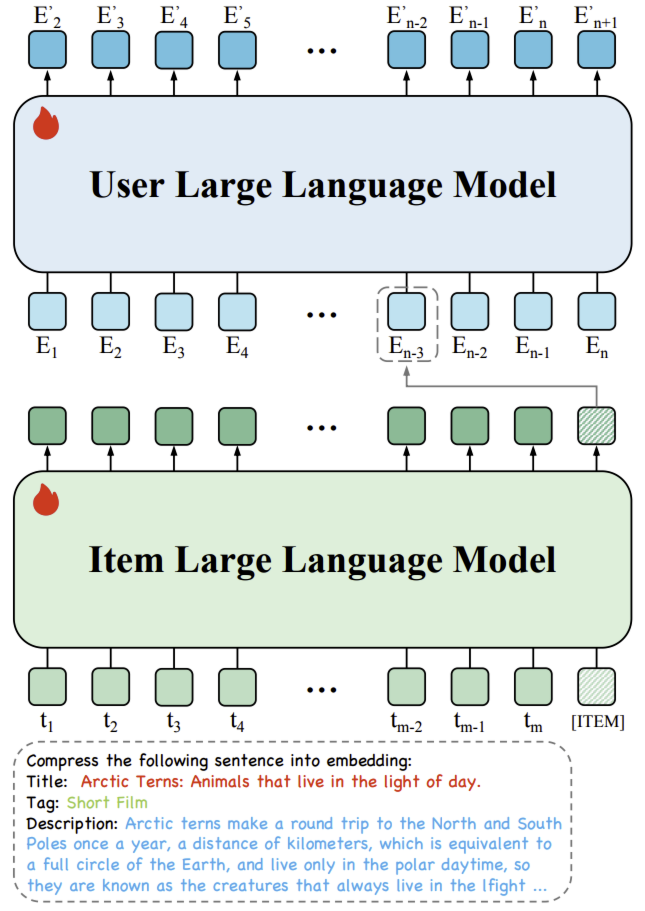
目前,相当多基于 LLM 的推荐模型会将用户的历史行为扁平化为纯文本输入传递给 LLM。这会导致输入序列过长,并且由于 LLM 中的自注意力模块,其复杂度会随输入序列长度呈二次方增长。为减轻用户序列建模的负担,HLLM 采用一种层次化建模方法,将物品建模与用户建模解耦。具体而言,我们首先通过物品LLM(Item LLM)提取物品特征,将复杂的文本描述压缩为嵌入表示;然后通过用户LLM(User LLM)基于这些物品特征建模用户画像。此外,为确保与预训练LLM的更好兼容性并增强可扩展性,我们仅引入少量结构修改,并设计简单且高效的训练目标。以下是物品建模和用户建模的详细介绍。
-
物品LLM(Item LLM)用于提取物品特征:以物品的文本描述作为输入,输出嵌入表示。LLM 在文本理解方面已展现出优异性能,但它们的应用大多局限于文本生成场景,很少有研究将其用作特征提取器。受先前研究的启发,HLLM 在物品文本描述的末尾添加一个特殊 token
[ITEM]来提取特征。具体来说,对于物品 $I$,首先将其对应的文本属性扁平化为句子 $T$,并在其前添加一个固定提示(prompt)。经过 LLM 分词器处理后,在末尾额外添加特殊token
[ITEM],因此物品 LLM 的输入 token 序列可表示为 ${t_1, t_2, \ldots, t_m, [\text{ITEM}]}$,其中 $m$ 表示文本 token 的长度。与特殊 token[ITEM]对应的最后一层隐藏状态被视为物品嵌入。 -
用户LLM(User LLM)用于建模用户兴趣:这是推荐系统的另一个关键方面。原始用户历史序列 $U = {I_1, I_2, \ldots, I_n}$ 可转换为历史特征序列 ${E_1, E_2, \ldots, E_n}$。
4.2、针对推荐目标的训练
现有 LLMs 均基于通用自然语言语料预训练。尽管它们具备丰富的世界知识和强大的推理能力,但其能力与推荐系统的需求之间仍存在显著差距。HLLM 在预训练 LLM 的基础上采用有监督微调。
推荐系统可分为生成式推荐和判别式推荐两类。HLLM 架构适用于这两种类型,仅需对训练目标进行适当调整。
4.2.1、生成式推荐
上节 Meta 的生成式推荐方案涵盖检索和排序任务。HLLM 的方法与之有两处主要差异:模型架构升级为带预训练权重的大型语言模型,输入特征从 ID 改为 LLM 可处理的文本特征。上述差异对训练和服务策略的影响极小,因此 HLLM 在很大程度上沿用 Meta 中提出的方法。
生成式推荐的训练目标采用下一个物品预测,即给定用户历史中前序物品的嵌入,生成下一个物品的嵌入。训练过程中使用 InfoNCE 损失。对于用户 LLM 输出序列中的任意预测嵌入 $E’_{i}$,正样本为 $E_i$,负样本从数据集中随机采样(排除当前用户序列)。损失函数公式如下:
\[\mathcal{L}_{\text{gen}} = -\sum_{j=1}^{b}\sum_{i=2}^{n} \log \frac{e^{s(E'_{j,i}, E_{j,i})}}{e^{s(E'_{j,i}, E_{j,i})} + \sum_{k}^{N} e^{s(E'_{j,i}, E_{j,i,k})}} \tag{1}\]其中:
- $s$ 为带可学习温度参数的相似度函数;
- $E_{j,i}$ 表示第 $j$ 个用户的历史交互中,由物品 LLM 生成的第 $i$ 个物品嵌入;
- $E’_{j,i}$ 表示用户 LLM 为第 $j$ 个用户预测的第 $i$ 个物品嵌入;
- $N$ 为负样本数量;
- $E_{j,i,k}$ 表示 $E’_{j,i}$ 的第 $k$ 个负嵌入;
- $b$ 为批次内的用户总数;
- $n$ 为用户历史交互序列的长度。
4.2.2、判别式推荐
由于判别式推荐模型在工业界仍占主导地位,字节也提出了 HLLM 在判别式推荐模型中的应用方案。判别式模型的优化目标是:给定用户序列 $U$ 和目标物品 $I_{\text{tgt}}$,判断用户是否对目标物品感兴趣(例如点击、点赞、购买等)。
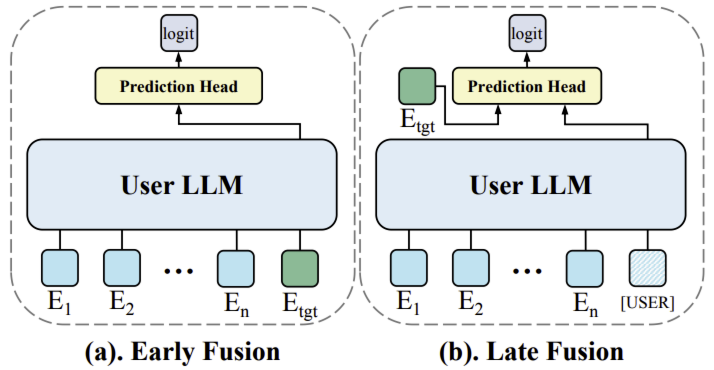
如图所示,判别式推荐中用户 LLM 有两种变体,而物品 LLM 保持不变:
- 早期融合(Early fusion):将目标物品嵌入 $E_{\text{tgt}}$ 附加到用户历史序列末尾,通过用户 LLM 生成高阶交叉特征,最终将该交叉特征输入预测头生成最终 logit。
- 晚期融合(Late fusion):先通过用户 LLM 提取与目标物品无关的用户特征(类似物品 LLM 的特征提取方式),在用户序列末尾添加特殊 token
[USER]以提取用户表征;再将用户嵌入与目标物品嵌入一同输入预测头,预测最终 logit。
早期融合由于深度整合了用户兴趣与目标物品,性能通常更优,但难以同时应用于大量候选物品;相反,晚期融合因不同候选物品共享相同的用户特征而更高效,但性能通常会下降。
判别式推荐的训练目标通常是分类任务(如预测用户是否点击)。以二分类为例,训练损失如下:
\[\mathcal{L}_{\text{cls}} = -\left( y \cdot \log(x) + (1 - y) \cdot \log(1 - x) \right) \tag{2}\]其中,$y$ 为训练样本的标签,$x$ 为预测的 logit。
实践中,下一个物品预测也可作为判别式模型的辅助损失,进一步提升性能。因此,最终损失公式如下:
\[\mathcal{L}_{\text{dis}} = \lambda \mathcal{L}_{\text{gen}} + \mathcal{L}_{\text{cls}} \tag{3}\]其中,$\lambda$ 控制辅助损失的权重。
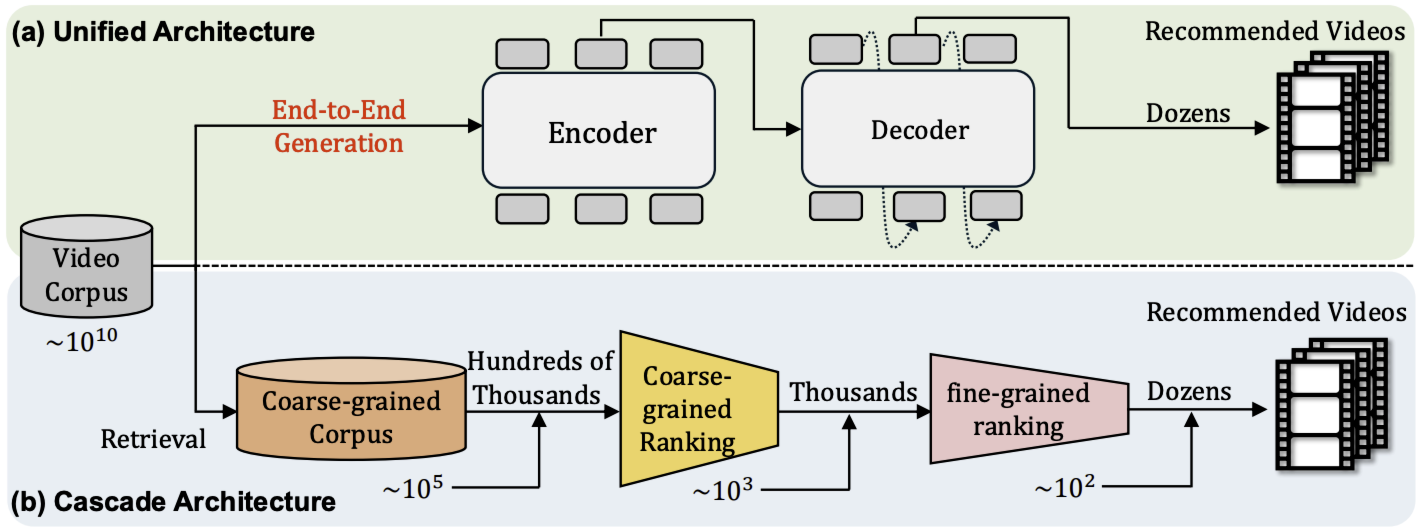
5、快手:OneRec
OneRec:
1)编码器 - 解码器结构。 对用户的历史行为序列进行编码,并逐步解码出用户可能感兴趣的视频。采用稀疏专家混合模型(MoE),在不按比例增加计算量(FLOPs)的情况下提升模型容量。
2)会话级生成方法。 与传统的 next-item prediction 不同,OneRec 提出会话级生成,相比依赖手工规则来合理组合生成结果的逐点生成,这种方法更简洁且上下文更连贯。
3)迭代偏好对齐模块,结合直接偏好优化(DPO)以提升生成结果的质量。与 NLP 中的 DPO 不同,推荐系统通常对每个用户的浏览请求只有一次展示结果的机会,因此无法同时获取正负样本。为解决这一限制,OneRec 设计了一个奖励模型来模拟用户生成过程,并根据推荐系统在线学习的特性定制采样策略。大量实验表明,少量 DPO 样本即可对齐用户兴趣偏好,并显著提升生成结果的质量。
5.1、基本方法
对于用户侧特征,OneRec 以正向历史行为序列 $\mathcal{H}_u = {v_h^1, v_h^2, \ldots, v_h^n}$ 作为输入,其中 $v$ 表示用户有效观看或有过互动(如点赞、关注、分享)的视频,$n$ 为行为序列长度。OneRec 的输出是一个视频列表,由会话 $\mathcal{S} = {v_1, v_2, \ldots, v_m}$ 组成,其中 $m$ 为一个会话内的视频数量。
对于每个视频 $v_i$,用多模态嵌入 $e_i \in \mathbb{R}^d$ 对其进行描述,这些嵌入与真实的用户-物品行为分布对齐。基于预训练的多模态表示,现有生成式推荐框架采用 RQ-VAE 将嵌入编码为语义标记。然而,这种方法并非最优,因为其存在码本分布不均衡的问题,即所谓的 “沙漏现象”。
OneRec 采用一种多级平衡量化机制,通过残差 K 均值量化算法对 $e_i$ 进行转换。在第一层($l=1$),初始残差定义为 $r_i^1 = e_i$。在每一层 $l$,存在一个码本 $C_l = {c_l^1, \ldots, c_l^K}$,其中 $K$ 为码本大小。最接近的质心节点嵌入的索引通过 \(s_i^l = \arg\min_k \| r_i^l - c_l^k \| _2^2\) 生成,而对于下一层 $l+1$,残差定义为 $ r_i^{l+1} = r_i^l - c_l^{s_i^l} $。
因此,相应的码本标记通过分层索引生成:
\[\begin{array}{cl} \boldsymbol{s}_i^1=\arg \min _k\left\|\boldsymbol{r}_i^1-\boldsymbol{c}_k^1\right\|_2^2, & \boldsymbol{r}_i^2=\boldsymbol{r}_i^1-\boldsymbol{c}_{s_i^1}^1 \\ \boldsymbol{s}_i^2=\arg \min _k\left\|\boldsymbol{r}_i^2-\boldsymbol{c}_k^2\right\|_2^2, & \boldsymbol{r}_i^3=\boldsymbol{r}_i^2-\boldsymbol{c}_{s_i^2}^2 \\ \vdots & \\ \boldsymbol{s}_i^L=\arg \min _k\left\|\boldsymbol{r}_i^L-\boldsymbol{c}_k^L\right\|_2^2 & \end{array}\]其中 $L$ 为语义 ID 的总层数。

为构建平衡的码本 $\mathcal{C}_l = {c_l^1, \ldots, c_l^K}$,采用算法 1 中详细描述的平衡 K 均值进行物品集划分。给定总视频集 $\mathcal{V}$,该算法将其划分为 $K$ 个聚类,每个聚类恰好包含 \(w = \mid \mathcal{V} \mid /K\) 个视频。在迭代计算过程中,每个质心会基于欧氏距离依次分配 $w$ 个最近的未分配视频,随后使用已分配视频的均值向量对质心进行重新校准。当聚类分配达到收敛时,终止条件满足。
5.2、会话级列表生成(Session-wise List Generation)
与仅预测下一个视频的传统 point-wise 推荐方法不同,会话级生成旨在基于用户的历史交互序列生成一系列高价值会话,使推荐模型能够捕捉推荐列表中视频之间的依赖关系。具体而言,会话指的是响应用户请求返回的一批短视频,通常包含 5 到 10 个视频。会话内的视频通常会考虑用户兴趣、连贯性和多样性等因素。OneRec 制定了若干标准来识别高质量会话,包括:
- 用户在一个会话中实际观看的短视频数量大于或等于 5;
- 用户观看该会话的总时长超过特定阈值;
- 用户表现出互动行为,如对视频进行点赞、收藏或分享。
这种方法确保会话级模型能从真实的用户参与模式中学习,并捕捉会话列表中更准确的上下文信息。因此,会话级模型 $\mathcal{M}$ 的目标可形式化为:
\[\mathcal{S} := \mathcal{M}(\mathcal{H}_u) \tag{1}\]其中,$\mathcal{H}_u$ 由语义ID表示:$\mathcal{H}_u = {(s_1^1, s_2^1, \cdots, s_1^L), (s_1^2, s_2^2, \cdots, s_2^L), \cdots, (s_n^1, s_n^2, \cdots, s_n^L)}$,且 $\mathcal{S} = {(s_1^1, s_2^1, \cdots, s_1^L), (s_1^2, s_2^2, \cdots, s_2^L), \cdots, (s_m^1, s_m^2, \cdots, s_m^L)}$。
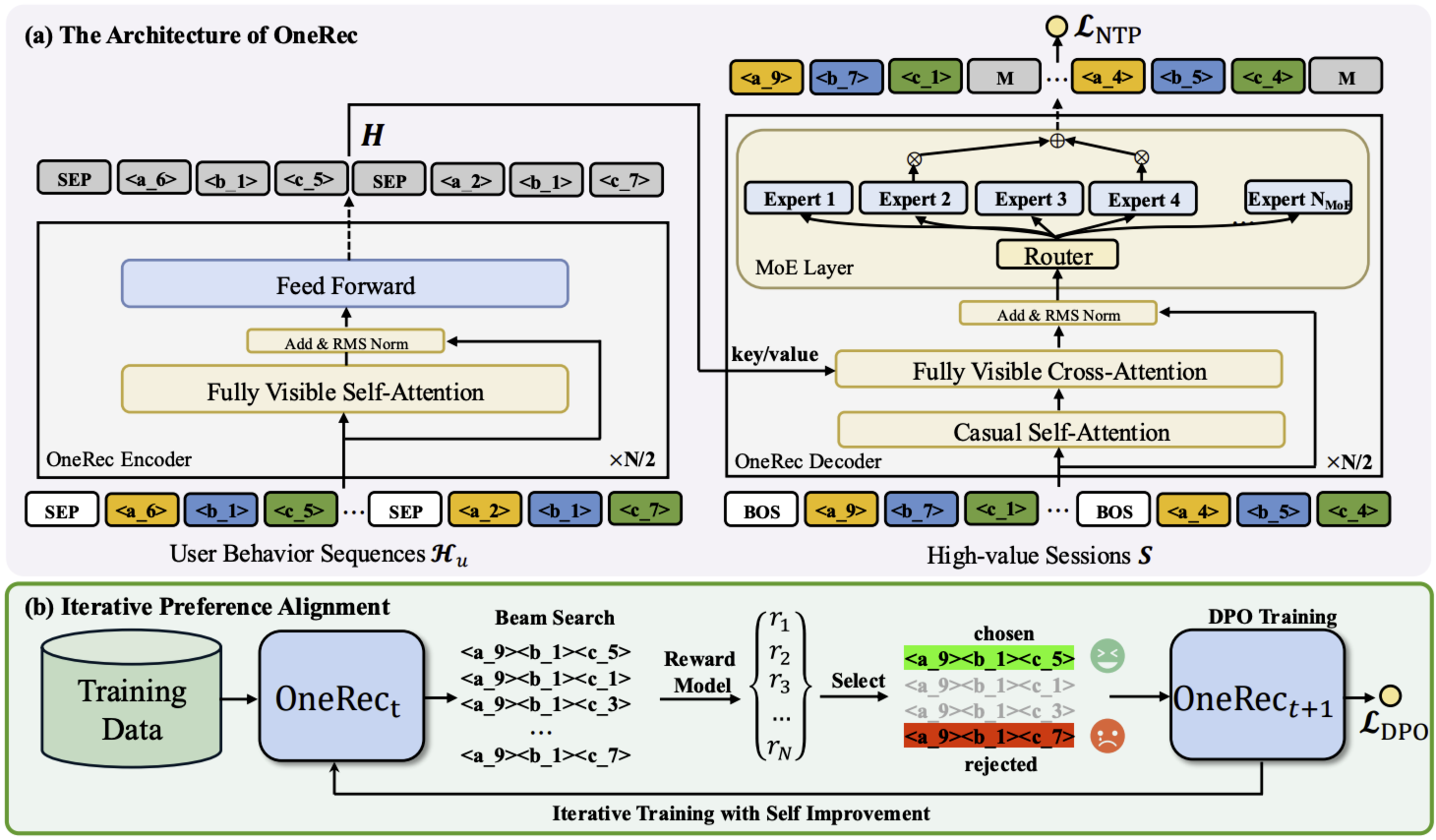
如上图(a)所示,与 T5 架构一致,OneRec 的模型采用基于 Transformer 的框架,包含两个主要组件:用于建模用户历史交互的编码器,以及用于会话列表生成的解码器。
具体而言,编码器利用堆叠的多头自注意力层和前馈层处理输入序列 $\mathcal{H}_u$。将编码后的历史交互特征记为 $H = \text{Encoder}(\mathcal{H}_u)$。解码器以目标会话的语义 ID 为输入,以自回归方式生成目标序列。为在合理的经济成本下训练更大的模型,对于解码器中的前馈神经网络(FNN),OneRec 采用基于 Transformer 的语言模型中常用的 MoE 架构,并将第 $l$ 个 FFN 替换为:
\[\begin{aligned} H_{t}^{l+1} &= \sum_{i=1}^{N_{\text{MoE}}} \Big( g_{i,t} \, \text{FFN}_i \big( H_{t}^{l} \big) \Big) + H_{t}^{l}, \\ g_{i,t} &= \begin{cases} s_{i,t} & , \, s_{i,t} \in \text{Topk}(\{s_{j,t} \mid 1 \leq j \leq N\}, K_{\text{MoE}}), \\ 0 & , \, \text{otherwise}, \end{cases} \\ s_{i,t} &= \text{Softmax}_i \Big( H_{t}^{l \, T} e_l^i \Big), \end{aligned} \tag{2}\]其中,
- $N_{\text{MoE}}$ 表示专家总数
- $\text{FFN}_i(\cdot)$ 是第 $i$ 个专家 FFN
- $g_{i,t}$ 表示第 $i$ 个专家的门控值。门控值 $g_{i,t}$ 具有稀疏性,即 $N_{\text{MoE}}$ 个门控值中仅有 $K_{\text{MoE}}$ 个非零。这种稀疏性确保了 MoE 层内的计算效率,且每个标记仅会被分配给 $K_{\text{MoE}}$ 个专家进行计算
在训练时,OneRec 在编码的开头添加一个起始标记 $s_{[BOS]}$,以构建解码器输入:
\[\bar{\mathcal{S}} = \{s_{[BOS]}, s_1^1, s_2^1, \cdots, s_1^L, s_{[BOS]}, s_1^2, s_2^2, \cdots, s_2^L, \cdots, s_{[BOS]}, s_m^1, s_m^2, \cdots, s_m^L\} \tag{3}\]OneRec 利用交叉熵损失对目标会话的语义 ID 进行下一个标记预测。下一个标记预测(NTP)损失 $\mathcal{L}_{\text{NTP}}$ 定义为:
\[\mathcal{L}_{\text{NTP}} = -\sum_{i=1}^{m} \sum_{j=1}^{L} \log P\Big( s_{i}^{j+1} \mid [s_{[BOS]}, s_1^1, s_2^1, \cdots, s_1^L, \cdots, s_{[BOS]}, s_i^1, \cdots, s_i^j]; \Theta \Big). \tag{4}\]在会话级列表生成任务上经过一定量的训练后,得到初始模型 $\mathcal{M}_t$。
5.3、基于奖励模型(RM)的迭代偏好对齐
高质量会话提供了有价值的训练数据,使模型能够学习 “优质会话的构成”,从而保证生成视频的质量。在此基础上,OneRec 通过直接偏好优化(DPO)进一步增强模型能力。在传统 NLP 场景中,偏好数据由人工显式标注;然而,推荐系统中的偏好学习面临一个独特挑战 —— 用户-物品交互数据稀疏,这使得奖励模型(RM)成为必需。
因此,OneRec 引入会话级奖励模型,并通过改进传统 DPO,提出迭代式直接偏好优化,使模型能够实现自我提升。
5.3.1、奖励模型训练
用 $R(\mathcal{u}, S)$ 表示为不同用户筛选偏好数据的奖励模型。其中,输出 $r$ 代表用户 $u$(通常由用户行为表征)对会话 \(S = \{v_1, v_2, \ldots, v_m\}\) 的偏好奖励。为使奖励模型具备会话排序能力,首先提取会话 $S$ 中每个物品 $v_i$ 的目标感知表征 $e_i = v_i \odot \mathcal{u}$,其中 $\odot$ 表示目标感知操作(如针对用户行为的目标注意力)。由此,得到会话 $S$ 的目标感知表征 \(h = \{e_1, e_2, \ldots, e_m\}\)。
随后,会话内的物品通过自注意力层相互作用,融合不同物品间的必要信息:
\[h_f = \text{SelfAttention}(h W^Q_s, h W^K_s, h W^V_s) \tag{5}\]接下来,使用不同的塔(Tower)对多目标奖励进行预测,且奖励模型通过大量推荐数据预训练:
\[\begin{align*} \hat{r}^{swt} &= \text{Tower}^{swt}\left(\text{Sum}(h_f)\right), \quad \hat{r}^{vtr} = \text{Tower}^{vtr}\left(\text{Sum}(h_f)\right), \\ \hat{r}^{wtr} &= \text{Tower}^{wtr}\left(\text{Sum}(h_f)\right), \quad \hat{r}^{ltr} = \text{Tower}^{ltr}\left(\text{Sum}(h_f)\right), \\ &\quad \text{其中 } \text{Tower}(\cdot) = \text{Sigmoid}(\text{MLP}(\cdot)) \tag{6} \end{align*}\]在得到每个会话的所有预估奖励 $\hat{r}^{swt}, \ldots$ 和真实标签 $y^{swt}, \ldots$ 后,通过直接最小化二元交叉熵损失来训练奖励模型。损失函数 $\mathcal{L}_{RM}$ 定义如下:
\[\mathcal{L}_{RM} = -\sum_{swt,...}^{xtr} \left[ y^{xtr} \log(\hat{r}^{xtr}) + (1 - y^{xtr}) \log(1 - \hat{r}^{xtr}) \right] \tag{7}\]5.3.2、迭代偏好对齐
基于预训练的奖励模型 $R(\mathcal{u}, \mathcal{S})$ 和当前模型 $\mathcal{M}_t$,通过束搜索为每个用户生成 $N$ 个不同的响应:
\[\mathcal{S}_u^n \sim \mathcal{M}_t(\mathcal{H}_u) \quad \forall u \in \mathcal{U}, \, n \in [N] \tag{8}\]其中 $[N]$ 表示集合 \(\{1, 2, \ldots, N\}\),$\mathcal{H}_u$ 为用户历史。
随后,基于奖励模型 $R(\mathcal{u}, \mathcal{S})$ 计算每个响应的奖励:
\[r_u^n = R(\mathcal{u}, \mathcal{S}_u^n) \tag{9}\]接下来,构建偏好对 $D^{\text{pairs}}_t = (\mathcal{S}_u^w, \mathcal{S}_u^l, \mathcal{H}_u)$:选择奖励最高的赢家响应 $(\mathcal{S}_u^w, \mathcal{H}_u)$ 和奖励最低的输家响应 $(\mathcal{S}_u^l, \mathcal{H}_u)$。
基于这些偏好对,训练新模型 $M_{t+1}$——其初始化为 $M_t$,并通过融合 DPO 损失(用于从偏好对中学习)的损失函数进行更新。每个偏好对对应的损失如下:
\[\begin{align*} \mathcal{L}_{\text{DPO}} &= \mathcal{L}_{\text{DPO}}(\mathcal{S}_u^w, \mathcal{S}_u^l | \mathcal{H}_u) \\ &= -\log \sigma\left( \beta \log \frac{M_{t+1}(\mathcal{S}_u^w | H_u)}{M_t(\mathcal{S}_u^w | \mathcal{H}_u)} - \beta \log \frac{M_{t+1}(\mathcal{S}_u^l | \mathcal{H}_u)}{M_t(\mathcal{S}_u^l | \mathcal{H}_u)} \right) \tag{10} \end{align*}\]整个流程涉及训练一系列模型 $M_t, \ldots, M_T$。为减轻束搜索推理的计算负担,仅随机采样 1% 的数据($r_{\text{DPO}} = 1\%$)用于偏好对齐。每个后续模型 $M_{t+1}$ 均从之前的模型 $M_t$ 初始化,并利用 $M_t$ 生成的偏好数据 $D^{\text{pairs}}_t$ 进行训练。

5.4、系统部署
在稳定性与性能之间取得平衡后,快手部署了 OneRec-1B 用于在线服务。如图所示,部署架构包含三个核心组件:1)训练系统、2)在线服务系统、3)DPO 样本服务器。
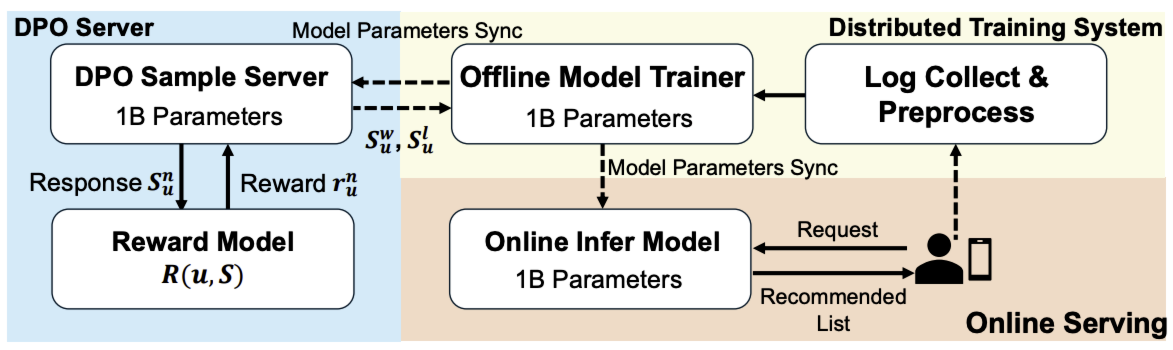
系统将收集到的交互日志作为训练数据,初期采用 next token prediction 目标 \(\mathcal{L}_{\text{NTP}}\) 训练种子模型。模型收敛后,加入 DPO 损失 \(\mathcal{L}_{\text{DPO}}\) 进行偏好对齐,并利用 XLA(加速线性代数)和 bfloat16 混合精度训练优化计算效率和内存使用。训练好的参数会同步至在线推理模块和 DPO 采样服务器,用于实时服务和基于偏好的数据筛选。
为提升推理性能,实施了两项关键优化:结合键值缓存解码机制与 float16 量化以减少 GPU 内存开销;配置束大小为 128 的束搜索,平衡生成质量与延迟。此外,得益于 MoE(混合专家)架构,推理过程中仅激活 13% 的参数。
6、快手:OneRec-V2
OneRec-V1 存在两大关键挑战制约其可扩展性与性能:
-
编码器-解码器架构中的计算资源分配效率低下:OneRec-V1 采用编码器 - 解码器框架:用户历史交互序列先通过编码器处理,再由解码器通过交叉注意力机制加以利用。尽管解码器参数数量多于编码器,但计算负载主要集中在编码器上 —— 因为编码器需处理大量用户交互序列,而解码器的输入长度则短得多。由于大部分计算预算被用于序列编码,而非制定推荐决策的关键生成过程,因此在同等计算预算下,这种失衡的资源分布可能会限制模型向更大架构有效扩展的潜力。
-
完全依赖奖励模型的强化学习存在局限性:基于奖励模型的强化学习在策略优化方面具有有效性,但该方法仍面临两个固有挑战。
- 采样效率有限:依赖奖励模型的方法需要额外计算资源用于在线生成与评分,这使得采样只能覆盖一小部分用户,以近似模拟全局用户行为
- 存在奖励作弊(reward hacking)风险:策略可能会学会利用奖励模型中的特定模式或偏差,而这些模式或偏差并不能转化为实际效果的提升
为解决上述挑战,OneRec-V2 优化如下:
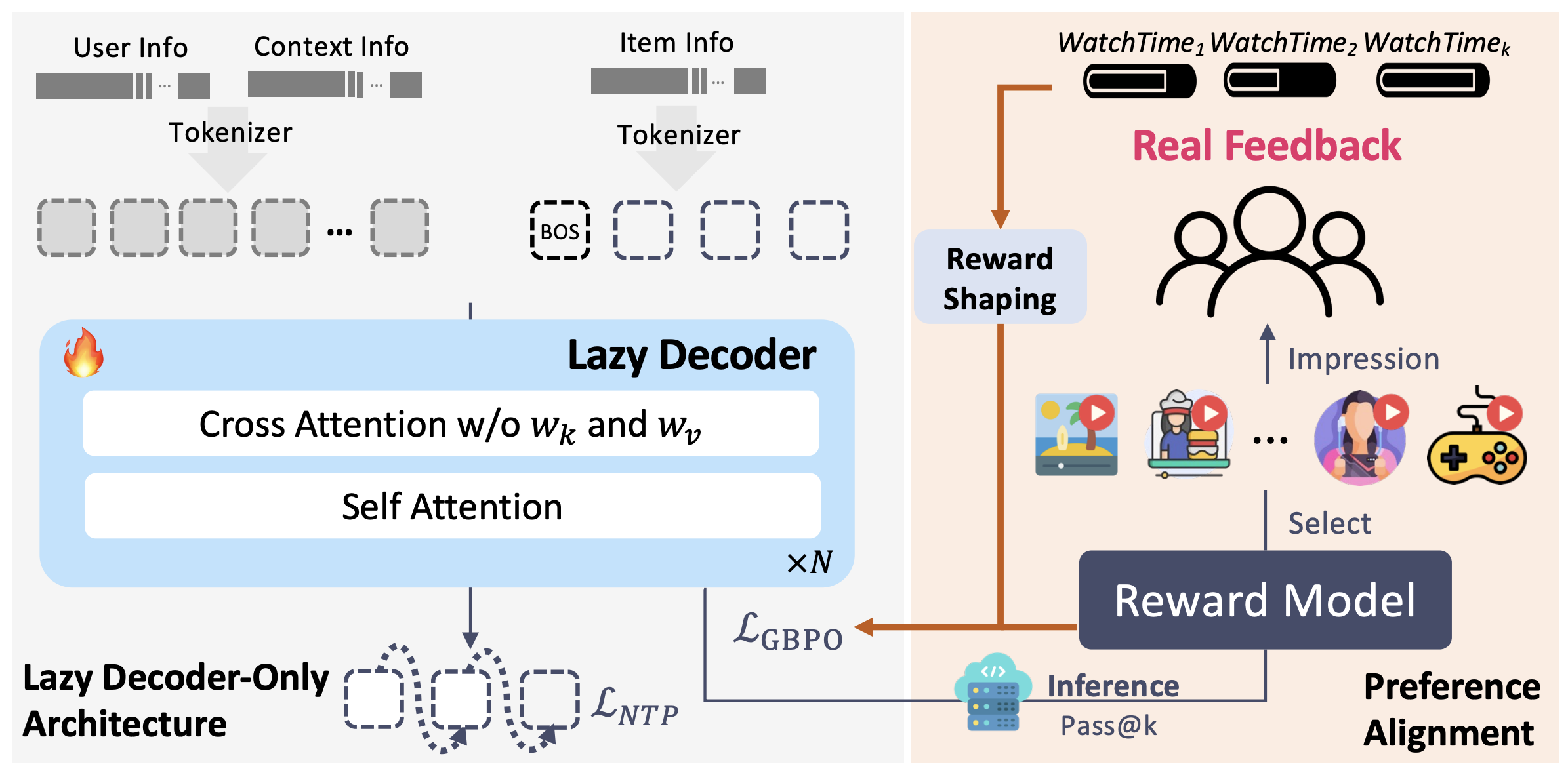
- 惰性纯解码器架构(Lazy Decoder-Only Architecture):用精简的纯解码器架构,消除了传统编码器 - 解码器设计的计算瓶颈。通过移除编码器组件并简化交叉注意力机制(去除键/值投影层,即K/V投影层),该惰性解码器的计算需求减少 $94\%$,实际训练资源消耗降低 $90\%$;同时在同等计算预算下,模型参数规模可提升 $\text{16}\times$(从 $\text{0.5B}$ 扩展至 $\text{8B}$)。
- 基于真实用户交互的偏好对齐:直接利用真实用户反馈信号,解决生成式推荐系统中奖励建模的根本性挑战。该框架包含两部分:
- 时长感知奖励塑造(Duration-Aware Reward Shaping):通过考虑视频时长差异,缓解原始观看时长信号中固有的偏差,确保奖励信号准确反映内容质量而非单纯依赖时长
- 自适应比例裁剪(Adaptive Ratio Clipping):在策略优化过程中,有效降低训练方差,同时保障模型收敛性
6.1、惰性纯解码器架构(Lazy Decoder-Only Architecture)
6.1.1、设计原则
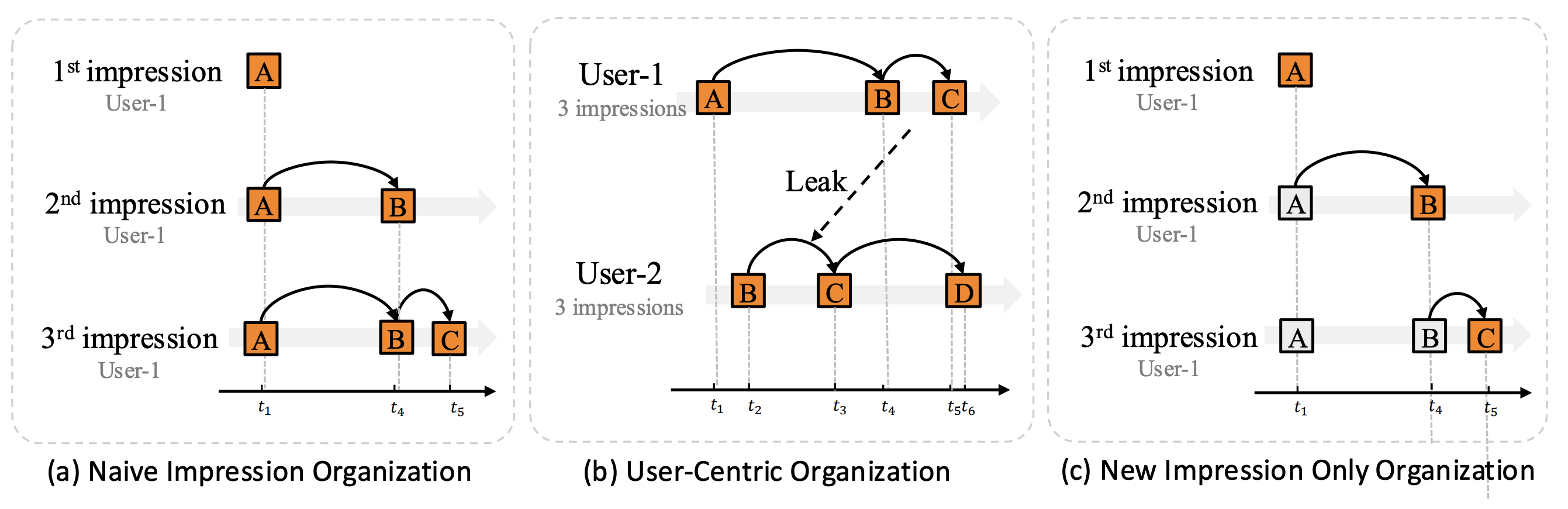
将这自回归架构适配于推荐系统,首要步骤是构建用于自回归训练的 “文档(doc)” 结构。传统上,推荐系统的训练样本按 “时间顺序的曝光记录” 组织,当与标准的 “下一个token预测(Next Token Prediction)” 目标结合时,会产生冗余问题。避免冗余的一种方式是采用 “以用户为中心的组织方式” —— 每个训练样本包含一名用户的完整交互历史,但这种方式存在 “时间数据泄露” 和 “流行度偏差” 的潜在风险。
为解决上述问题,OneRec-V2 提出:按时间顺序组织数据,但仅对 “最新曝光的物品” 计算训练损失。如上图 c 所示,灰色标注的物品不参与下一个 token 的预测。由于 “历史物品” 与 “最新曝光物品” 在训练中发挥的作用不同,在早期的 OneRec-V1 中选择了编码器 - 解码器(Encoder-Decoder)架构。对该架构的计算过程划分为两类:上下文编码(Context Encoding) 与 目标解码(Target Decoding)。
定义1 上下文编码(Context Encoding):指对用户上下文特征进行处理和转换的计算操作,具体包括:(i)在编码器中执行的上下文转换操作;(ii)在解码器交叉注意力机制中执行的上下文投影操作。
定义2 目标解码(Target Decoding):指在解码器中对目标物品的语义 token 进行处理和转换的计算操作,具体包括:(i)捕捉语义 token 间依赖关系的自注意力(self-attention);(ii)执行非线性转换的前馈网络(feed-forward network, FFN);(iii)交叉注意力机制中的查询(query)转换与输出转换操作。
在参数数量相同的情况下,编码器-解码器架构相比传统纯解码器架构节省了近一半的计算量。然而,这两种架构仍存在计算效率低下的问题:大部分计算资源被分配给了对 “损失计算无直接贡献” 的 token。对于 OneRec-V1 中典型的上下文长度 $N = 512$,仅有不到 3% 的总浮点运算次数(FLOPs)用于损失计算;且随着上下文长度的增加,这一比例会变得愈发微不足道。为将计算资源完全集中于 “目标物品的语义token”,从而实现模型向更大规模的高效扩展,OneRec-V2 提出了惰性纯解码器架构。
6.1.2、整体架构
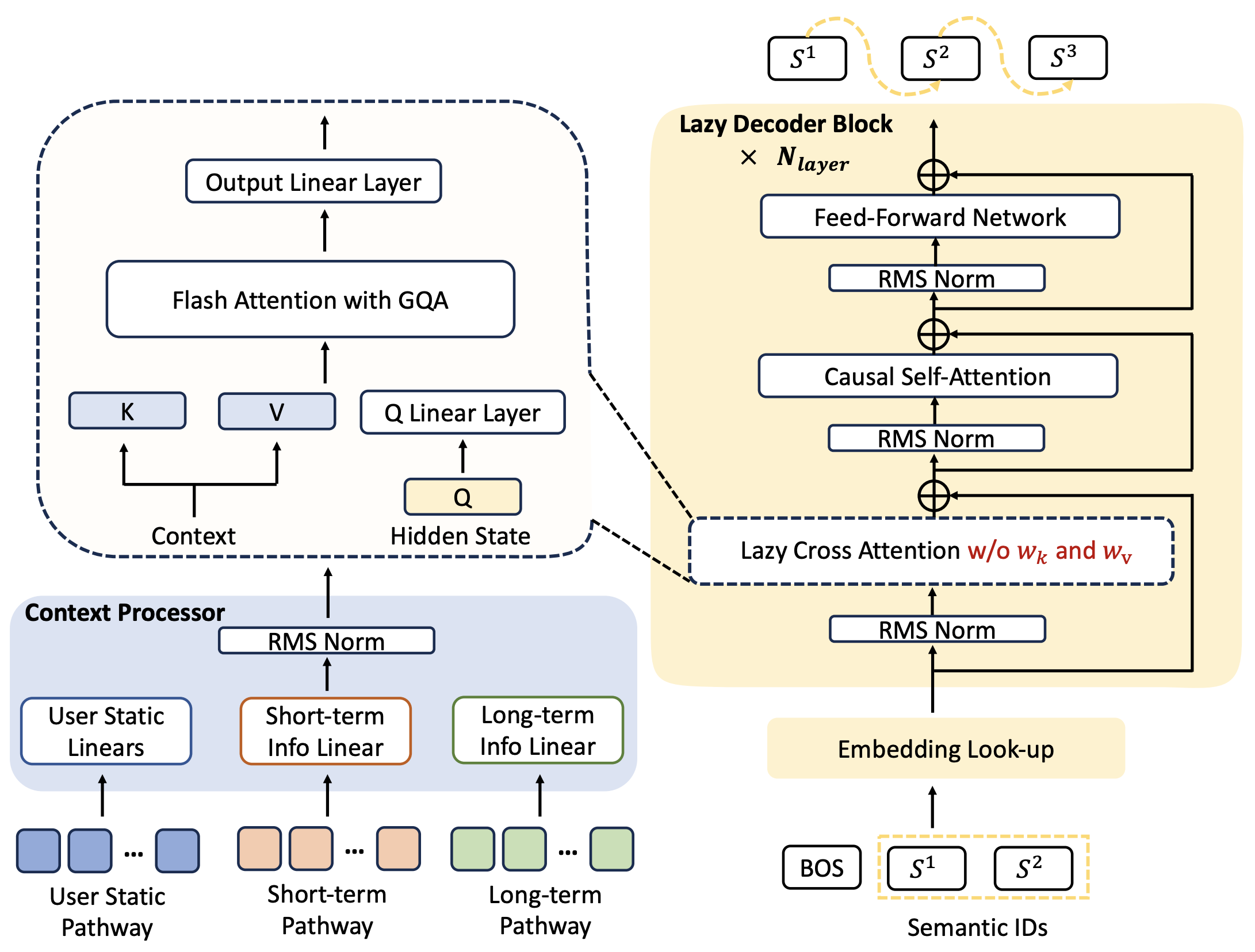
OneRec-V2 提出惰性纯解码器架构,既区别于传统的编码器 - 解码器模型,也不同于朴素的纯解码器方案。在设计中,上下文被视为 “静态条件信息”,仅通过交叉注意力机制调用,此举在保留模型捕捉复杂用户 - 物品交互能力的同时,消除了冗余计算。
其次,引入无键值投影(key-value projections)的高效惰性交叉注意力机制。结合分组查询注意力机制(Grouped Query Attention, GQA),该设计大幅降低了内存占用,使模型能够高效处理海量用户历史数据。
上下文处理器(Context Processor):
为有效整合异构、多模态的用户行为信号,OneRec-V2 设计了一个统一模块 —— 上下文处理器,使其能与下游基于注意力机制的解码器块实现无缝衔接。
具体而言,用户画像、用户行为等异构输入会被拼接为一个统一序列(即 “上下文”)。上下文序列中的每个物品都会被处理为相同维度,满足:
\[d_{\text{context}} = S_{\text{kv}} \cdot L_{\text{kv}} \cdot G_{\text{kv}} \cdot d_{\text{head}}, \tag{1}\]其中,$d_{\text{head}}$ 表示注意力头维度,$G_{\text{kv}}$ 表示键值头组数,$S_{\text{kv}}$ 表示键值分割系数,$L_{\text{kv}}$ 表示键值层数。
上下文表示会被转换为 “与层相关的键值对”,以供注意力机制使用。沿特征维度对上下文张量进行划分,生成 $L_{\text{kv}}$ 组键值对:
\[\text{Context} = [C_0, C_1, \dots, C_{S_{\text{kv}} \cdot L_{\text{kv}} - 1}], \tag{2}\]其中,$C_{S_{\text{kv}} \cdot L_{\text{kv}} - 1} \in \mathbb{R}^{G_{\text{kv}} \cdot d_{\text{head}}}$。为简化表述,此处忽略了序列维度。
对于每一层 \(l \in \{0, 1, \dots, L_{\text{kv}} - 1\}\),计算归一化后的键值对:
\[k_l = \text{RMSNorm}_{k,l} \left( C_{l \cdot S_{\text{kv}}} \right), \tag{3}\] \[v_l = \begin{cases} \text{RMSNorm}_{v,l} \left( C_{l \cdot S_{\text{kv}} + 1} \right), & \text{若 } S_{\text{kv}} = 2 \text{(键值分离)} \\ k_l, & \text{若 } S_{\text{kv}} = 1 \text{(表示共享)} \end{cases}. \tag{4}\]上下文处理器的最终输出为 \(\{(k_0, v_0), \dots, (k_{L_{\text{kv}} - 1}, v_{L_{\text{kv}} - 1})\}\)。
惰性解码器块(Lazy Decoder Block):
分词器(Tokenizer):
对于每个目标物品,采用语义分词器生成 3 个语义 ID,以捕捉物品的多维度特征。训练阶段,使用前 2 个语义 ID,并在序列开头添加一个序列起始(beginning-of-sequence, BOS)token,构成输入序列。随后,这些 token 索引通过嵌入表映射为初始隐藏表示:
\[h^{(0)} = \text{Embed}([\text{BOS}, s_1, s_2]) \in \mathbb{R}^{3 \times d_{\text{model}}}. \tag{5}\]块结构(Block Structure):
惰性解码器由 $N_{\text{layer}}$ 个堆叠的 Transformer 块组成,每个块包含三个核心组件:交叉注意力模块、自注意力模块和前馈网络模块。对于第 $l$ 层,其变换过程定义如下:
\[h^{(l)}_{\text{cross}} = h^{(l-1)} + \text{CrossAttn} \left( \text{RMSNorm}(h^{(l-1)}), k_{l_{\text{kv}}}, v_{l_{\text{kv}}} \right), \tag{6}\] \[h^{(l)}_{\text{self}} = h^{(l)}_{\text{cross}} + \text{SelfAttn} \left( \text{RMSNorm}(h^{(l)}_{\text{cross}}) \right), \tag{7}\] \[h^{(l)} = h^{(l)}_{\text{self}} + \text{FFN}^{(l)} \left( \text{RMSNorm}(h^{(l)}_{\text{self}}) \right), \tag{8}\]其中,$\text{RMSNorm}$ 表示均方根层归一化,用于保证训练稳定性。
为在保持计算效率的同时提升模型容量,采用混合架构:将深层中的密集前馈网络(dense feed-forward networks)替换为专家混合(Mixture-of-Experts, MoE)模块。借鉴 DeepSeek-V3 的设计,采用无辅助损失(auxiliary-loss-free)的负载均衡策略,确保专家模块的高效利用。
惰性交叉注意力:键值共享(KV-Sharing):
为提升参数效率与计算效率,多个惰性解码器块共享由上下文处理器生成的同一组键值对。对于当前第 $l$ 层,通过以下公式确定对应的键值索引:
\[l_{\text{kv}} = \left\lfloor \frac{l \cdot L_{\text{kv}}}{N_{\text{layer}}} \right\rfloor, \tag{9}\]其中,$N_{\text{layer}}$ 表示惰性解码器块的总数量。该设计确保连续的解码器块共享相同的上下文表示 $(k_{l_{\text{kv}}}, v_{l_{\text{kv}}})$,且 $k_{l_{\text{kv}}}, v_{l_{\text{kv}}} \in \mathbb{R}^{(N_s + T_{\text{short}} + T_{\text{long}}) \times G_{\text{kv}} \times d_{\text{head}}}$。
进一步通过 “统一键值表示” 提升参数效率:对于所有层,均设置 $v_l = k_l$。这一设计的依据是:绑定的键值投影(tied key-value projections)在降低模型内存占用的同时,仍能保持相近的性能。
惰性交叉注意力:分组查询注意力(Grouped Query Attention):
查询投影(query projection)保持 $H_q = d_{\text{model}}/d_{\text{head}}$ 个注意力头,而键值对仅使用 $G_{\text{kv}}$ 个头组(通常满足 $G_{\text{kv}} < H_q$)。该设计大幅降低了两方面开销:一是上下文表示的内存占用,二是注意力计算过程中的内存访问需求,从而使模型能高效扩展至更长的上下文序列和更大的批次大小(batch sizes)。
输出层(Output Layer):
最后一个解码器块的输出隐藏表示,会经过 “位置特异性均方根层归一化(position-specific RMSNorm)” 和线性层(Linear layer)处理,生成每个语义 ID 的预测结果。训练阶段,通过优化模型,最大化目标物品语义ID $[s_1, s_2, s_3]$ 的生成概率。
6.2、基于真实用户交互的偏好对齐
此阶段的核心目的是捕捉用户实时兴趣变化,同时避免模型与预训练模型偏差过大。在 OneRec-V1 中,强化学习(RL)阶段完全依赖奖励模型;而在 OneRec-V2 中,引入了以用户反馈信号作为奖励的强化学习机制。
6.2.1、基于用户反馈信号的强化学习
基于用户反馈定义奖励,可避免奖励作弊(reward hacking)问题,且无需额外的模型计算开销。但该方式仍面临挑战:如何融合多目标、正样本标签稀疏性等。在短视频推荐场景中,每个视频的播放时长是密度最高的反馈信号,且与应用停留时长(APP Stay Time)、7日生命周期(LT7, Lifetime over 7 days)等核心在线指标高度相关。因此,OneRec-V2 基于播放时长设计了一种简洁且高效的奖励机制。
时长感知奖励塑造(Duration-Aware Reward Shaping):
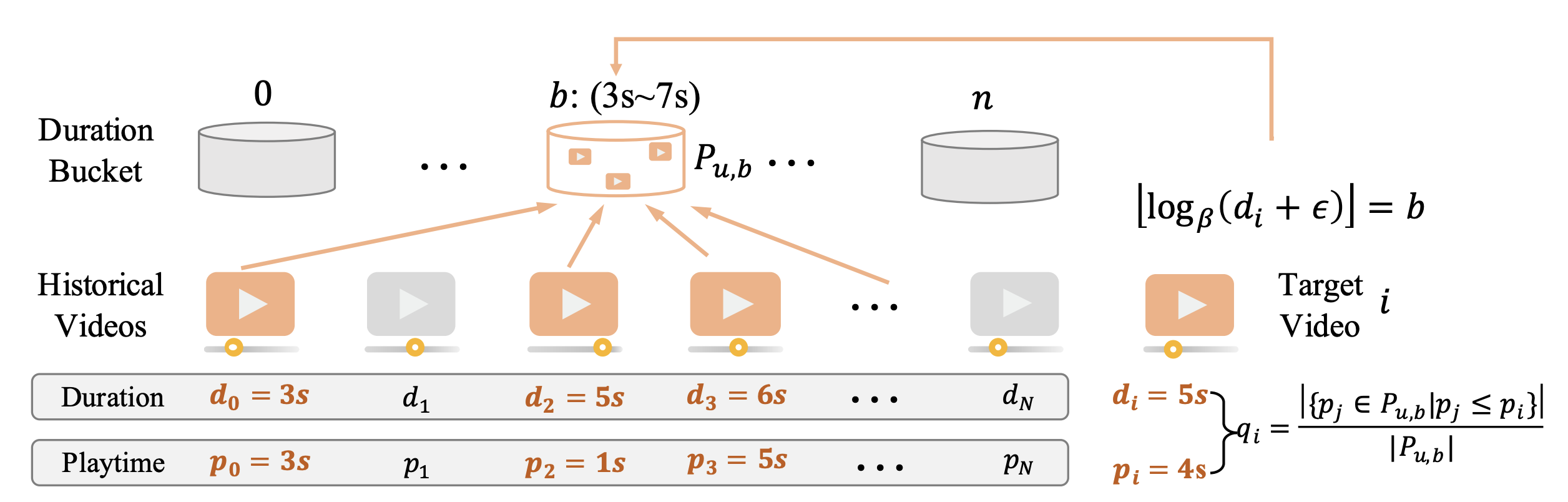
尽管视频播放时长是衡量用户满意度的有效指标,但其本质上会受到视频本身时长的偏差影响。为解决这一偏差,OneRec-V2 提出时长感知奖励塑造机制。该方法通过将当前视频的播放时长与 “用户历史中相同时长区间的视频” 进行对比,实现播放时长的归一化。由于视频时长服从长尾分布,采用对数策略将历史视频划分为不同桶(bucket)—— 该策略将时长归入 “指数级宽间隔” 中,从而形成更均衡、更具意义的对比组。
时长到桶的映射由函数 $F(d)$ 实现,该函数将时长为 $d$ 的视频分配到离散桶索引 $b \in B$ 中。形式上,桶划分函数定义为:
\[F(d) = \lfloor \log_\beta (d + \epsilon) \rfloor\]其中,$\beta$ 是控制桶粒度的可配置对数底数,$\epsilon$ 是为处理极短时长时保证数值稳定性而添加的小常数(例如 $\epsilon = 10^{-6}$)。
设 \(H_u = \{(d_k, p_k)\}_{k=1}^N\) 表示用户 $u$ 的历史交互序列,其中 $d_k$ 为视频时长,$p_k$ 为观测到的播放时长。对于每个时长桶 $b$,定义播放时长的经验分布为:
\[P_{u,b} = \{ p_j \mid (d_j, p_j) \in H_u, F(d_j) = b \}\]对于目标视频 $i$(时长 $d_i$、播放时长 $p_i$),首先通过 $b = F(d_i)$ 确定其所属桶;随后,时长归一化后的用户参与度得分(engagement score)定义为 $p_i$ 在用户历史分布 $P_{u,b}$ 中的经验百分位排名:
\[q_i = \frac{|\{ p_j \in P_{u,b} \mid p_j \leq p_i \}|}{|P_{u,b}|}\]基于该得分筛选高价值样本作为正样本:在一个批次中,将 $q_i$ 按降序排序后,取其 25% 分位数(上四分位数)作为阈值 $\tau_b$。对于存在 “不喜欢” 等明确负反馈的样本($neg_i = 1$),设 $A_i = -1$;其余样本均被过滤(等效于 $A_i = 0$)。需注意,直接赋值优势函数(advantage)值,未进行归一化 —— 因为对正、负样本的定义已足够严格,进一步归一化可能导致优化不一致,反而降低性能。形式上,优势函数定义如下:
\[A_i = \begin{cases} +1, & q_i > \tau_B \text{ 且 } neg_i = 0, \\ -1, & neg_i = 1, \\ 0, & \text{其他情况}. \end{cases}\]该策略可有效筛选高质量正样本,同时融入直接负反馈信号,从而获得更准确的用户偏好信号。
强化学习:
梯度有界策略优化(Gradient-Bounded Policy Optimization, GBPO)
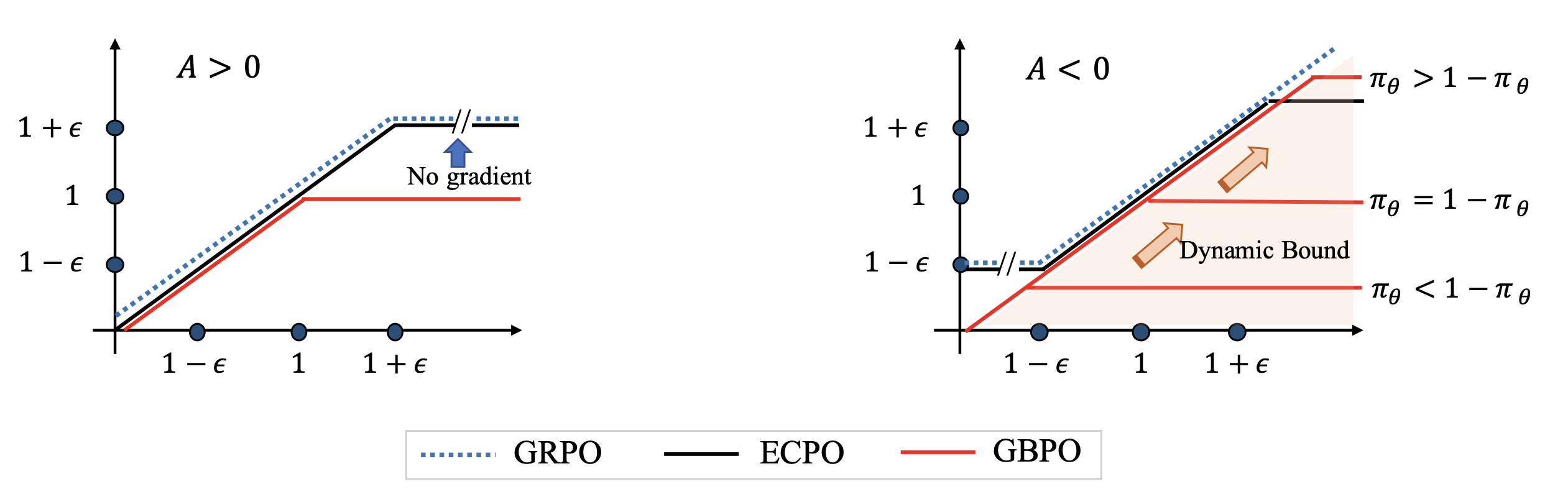
强化学习的有效性与稳定性是当前 LLM 领域的研究重点。核心挑战在于:如何在增强探索以提升性能的同时,维持梯度稳定。OneRec-V2 提出的新型强化学习方法 —— 梯度有界策略优化(GBPO)。其目标函数定义为:
\[J_{\text{GBPO}}(\theta) = -\mathbb{E}_{u \sim P(U), \{o_i\}_{i=1}^G \sim \pi_{\theta_{\text{old}}}} \left[ \frac{1}{G} \sum_{i=1}^G \frac{\pi_\theta(o_i \mid u)}{\pi'_{\theta_{\text{old}}}(o_i \mid u)} \cdot A_i \right], \tag{11}\] \[\pi'_{\theta_{\text{old}}}(o_i \mid u) = \begin{cases} \max(\pi_{\theta_{\text{old}}}, sg(\pi_\theta)), & A_i \geq 0, \\ \max(\pi_{\theta_{\text{old}}}, 1 - sg(\pi_\theta)), & A_i < 0. \end{cases} \tag{12}\](注:$sg(\cdot)$ 表示停止梯度(stop gradient)操作,用于固定某一变量的梯度传播。)
由公式可见,GBPO 移除了对 “策略比率(policy ratio)” 的裁剪操作,转而对 $\pi_{\theta_{\text{old}}}$ 引入动态边界。总体而言,GBPO 具备两大核心优势:
- 全样本利用:保留所有样本的梯度,鼓励模型进行更多样化的探索;
- 梯度有界稳定:利用二元交叉熵(BCE, Binary Cross-Entropy)损失的梯度对 RL 梯度进行约束,提升 RL 训练的稳定性。
现有基于裁剪的方法(Existing Clipping-based Work)
在详细介绍 GBPO 之前,先简要回顾 LLM 领域现有的 RL 方法。GRPO/PPO 通过裁剪操作丢弃 “策略比率过大或过小” 的样本,避免训练过于激进;DAPO 通过 “更高裁剪阈值(clip higher)” 放宽样本限制,尤其纳入更多低概率或高熵 token,从而在提升 RL 性能的同时增加多样性。这些研究表明:放宽裁剪约束以纳入更多样本,可鼓励更丰富的探索并提升性能。
然而,这些方法未能全面考虑梯度稳定性。特别是对于负样本,策略比率缺乏上界约束易导致梯度爆炸,进而引发模型性能崩溃。Dual-clip 方法对负样本的策略比率施加上界截断 —— 虽提升了稳定性,但丢弃了过多负样本,减缓收敛速度。在 OneRec-V1 中提出了早期裁剪 GRPO(ECPO):对负样本的梯度上界进行截断,从而在保留更多样本的同时增强稳定性。其目标函数定义为:
\[J_{\text{ECPO}}(\theta) = -\mathbb{E}_{u \sim P(U), \{o_i\}_{i=1}^G \sim \pi_{\theta_{\text{old}}}} \left[ \frac{1}{G} \sum_{i=1}^G \min\left( \frac{\pi_\theta(o_i \mid u)}{\pi'_{\theta_{\text{old}}}(o_i \mid u)} A_i, \text{clip}\left( \frac{\pi_\theta(o_i \mid u)}{\pi'_{\theta_{\text{old}}}(o_i \mid u)}, 1 - \epsilon, 1 + \epsilon \right) A_i \right) \right], \tag{13}\] \[\pi'_{\theta_{\text{old}}}(o_i \mid u) = \max\left( \frac{sg(\pi_\theta(o_i \mid u))}{1 + \epsilon + \delta}, \pi_{\theta_{\text{old}}}(o_i \mid u) \right), \quad \delta > 0. \tag{14}\]梯度分析(Gradient Analysis)
曝光样本包含两部分:OneRec 生成的样本、传统推荐流水线(pipeline)生成的样本。对于 OneRec 生成的样本,将其曝光时的生成概率作为 $\pi_{\text{old}}$;对于传统流水线生成的样本,由于流水线逻辑复杂,无法获取其原始概率,因此简化设 $\pi_{\text{old}} = sg(\pi_\theta)$(即 OneRec 模型当前的生成概率)。对于这类简化样本,其策略比率恒为 1。
在传统 RL 方法中,比率为 1 的样本被视为训练稳定样本,不进行截断。但实际中,此类样本仍可能因负样本导致梯度爆炸。
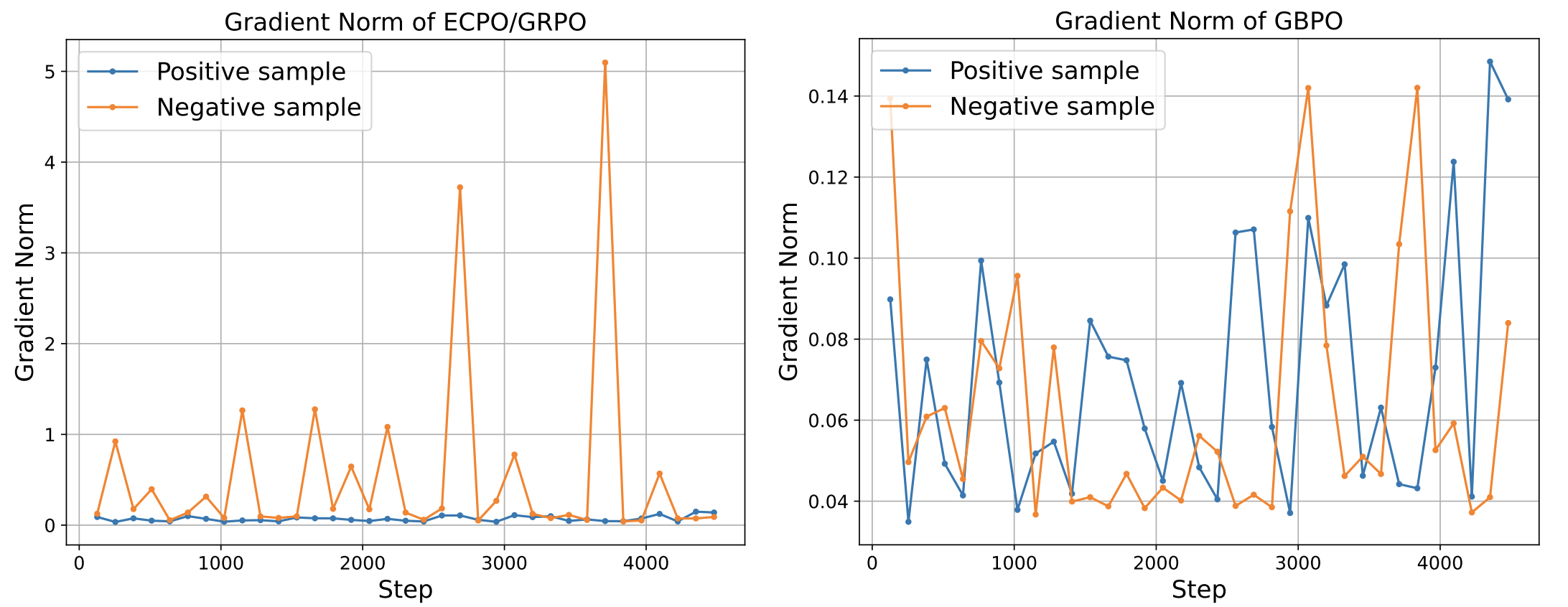
从梯度角度分析,对于这类样本的某一特定 token $i$,ECPO 的损失与梯度可表示为:
\[J^i_{\text{ECPO}}(\theta) = -A_i \cdot \frac{\pi_\theta}{sg(\pi_\theta)}, \tag{15}\] \[\frac{\partial J^i_{\text{ECPO}}(\theta)}{\partial \theta} = -A_i \cdot \frac{1}{\pi_\theta} \cdot \frac{\partial \pi_\theta}{\partial \theta}, \tag{16}\]这表明:当前 token 概率 $\pi_\theta$ 越小,梯度越大。对于正样本,概率越小意味着提升空间越大,因此梯度较大具有合理性;但对于负样本,概率越小意味着抑制空间越小 —— 若梯度过大,易导致模型过拟合甚至性能崩溃。这一现象说明:传统裁剪方法无法彻底解决 RL 梯度不稳定问题,因为它们无法避免 “比率为 1 时” 的梯度爆炸。
在 BCE 损失中,虽同样对负样本存在惩罚,但其梯度远比 RL 损失稳定。BCE 损失及其梯度定义为:
\[L_{\text{BCE}}(y, p_\theta) = - \left[ y \cdot \log(p_\theta) + (1 - y) \cdot \log(1 - p_\theta) \right], \tag{17}\] \[\frac{\partial L_{\text{BCE}}}{\partial \theta} = \begin{cases} - \frac{1}{p_\theta} \cdot \frac{\partial p_\theta}{\partial \theta}, & y = 1, \\ \frac{1}{1 - p_\theta} \cdot \frac{\partial p_\theta}{\partial \theta}, & y = 0. \end{cases} \tag{18}\]对于负样本($y=0$),当前模型概率越小,抑制该样本时的梯度也越小,从而使模型更稳定。基于这一观察提出 GBPO:利用 BCE 损失更稳定的梯度对 RL 梯度进行约束。不同方法的梯度差异如下图所示。
7、百度:COBRA
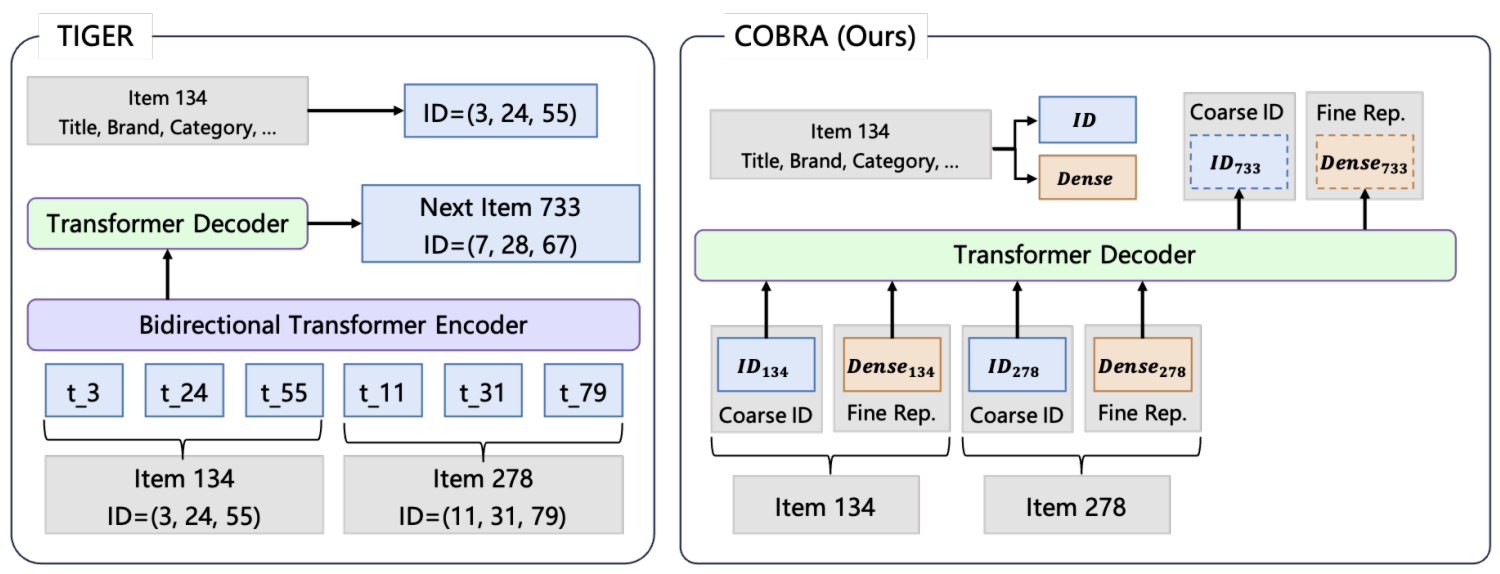
COBRA:
Cascaded Bi-Represented Retrieval Framework:在生成稀疏语义 ID 和稠密向量之间交替进行。通过将稠密表征融入 ID 序列,COBRA 弥补了基于 ID 的方法中固有的信息损失;而将稀疏 ID 作为生成稠密向量的条件,则降低了稠密表征的学习难度。
端到端训练学习稠密表征:COBRA 以原始物品数据为输入,通过端到端训练生成稠密表征。与静态嵌入不同,COBRA 的稠密向量是动态学习的,能够捕捉语义信息和细粒度细节。
从粗到细的生成过程:推理时首先生成稀疏 ID,然后将这些 ID 反馈到模型中以生成精细化的稠密表征,从而提升稠密向量的粒度。
7.1、稀疏-稠密表征
7.1.1、稀疏表征
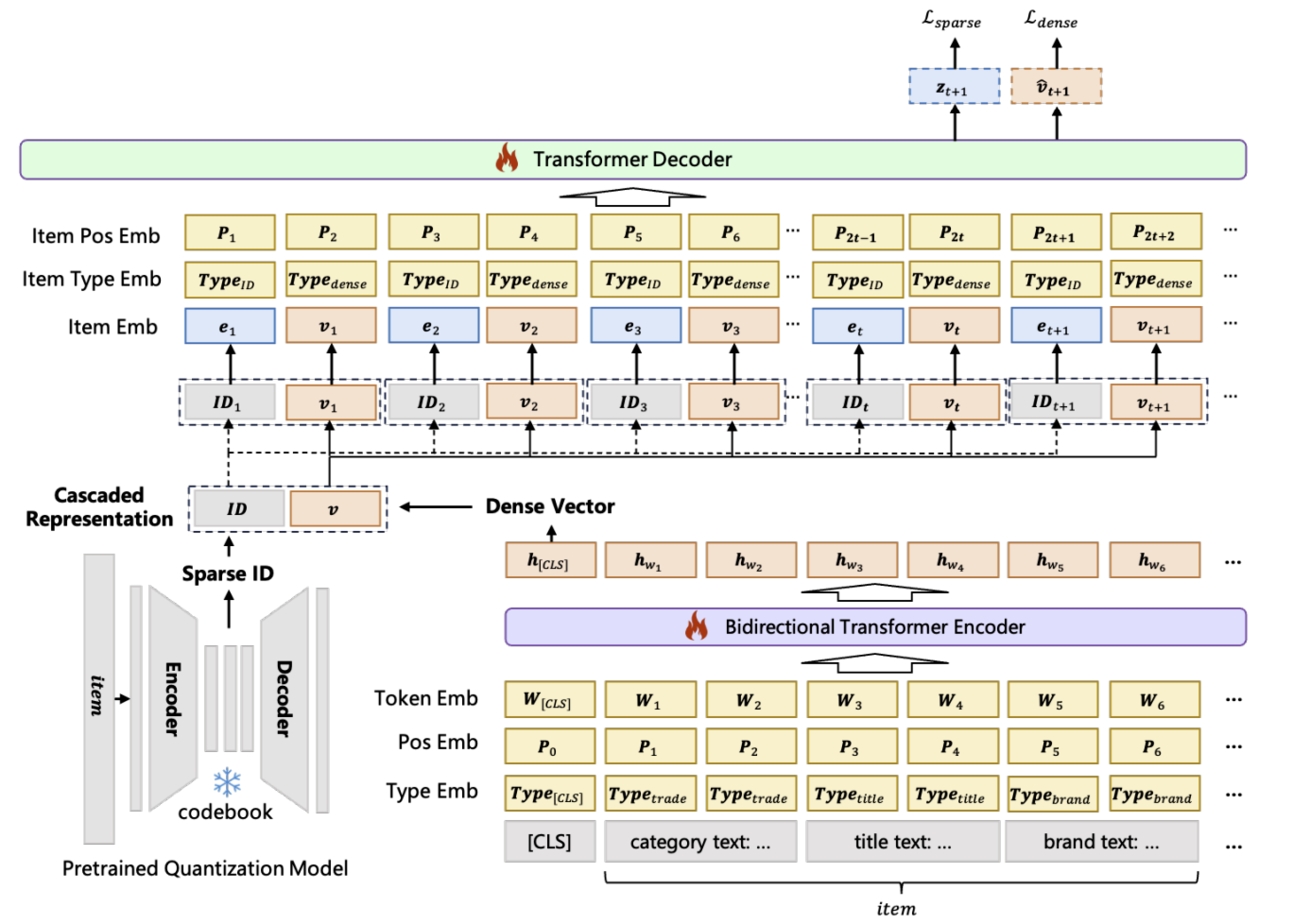
COBRA 借鉴 TIGER 的方法,使用残差量化变分自编码器(Residual Quantized Variational Autoencoder, RQ-VAE)生成稀疏 ID。对于每个物品,提取其属性生成文本描述,将该描述嵌入到稠密向量空间中并进行量化,从而得到稀疏 ID。这些 ID 捕捉了物品的类别本质,为后续处理奠定基础。为简洁起见,后续方法描述将假设稀疏 ID 仅包含单一层级,但需注意,该方法可轻松扩展至包含多个层级的场景。
7.1.2、稠密表征
为捕捉细致的属性信息,COBRA 设计了一个端到端可训练的稠密编码器,用于对物品文本内容进行编码。每个物品的属性被扁平化为一个文本句子,前缀添加 [CLS] 标记后输入基于 Transformer 的文本编码器 Encoder。稠密表征 $v_t$ 从 [CLS] 标记对应的输出中提取,用于捕捉物品文本内容的细粒度细节。
如上图下半部分所示,COBRA 引入位置嵌入和类型嵌入,用于建模序列中标记的位置和上下文信息。这些嵌入以加法方式与标记嵌入结合,增强模型区分不同标记及其在序列中位置的能力。
7.1.3、级联表征
级联表征在统一的生成模型中整合了稀疏 ID 和稠密向量。具体而言,对于每个物品,将其稀疏 ID $ID_t$ 和稠密向量 $v_t$ 组合,形成级联表征 $(ID_t, v_t)$。这种方法融合了两种表征的优势,提供了更全面的物品刻画:稀疏 ID 通过离散约束提供稳定的类别基础,而稠密向量则保持连续的特征分辨率,确保模型同时捕捉高层语义和细粒度细节。
7.2、序列建模
7.2.1、概率分解
目标物品的概率分布建模被分解为两个阶段,以利用稀疏表征和稠密表征的互补优势。具体而言,COBRA 并非基于历史交互序列 $S_{1:t}$ 直接预测下一个物品 $s_{t+1}$,而是分别预测稀疏ID $ID_{t+1}$ 和稠密向量 $v_{t+1}$:
\[P(ID_{t+1}, v_{t+1} | S_{1:t}) = P(ID_{t+1} | S_{1:t}) \cdot P(v_{t+1} | ID_{t+1}, S_{1:t}) \tag{1}\]其中,$P(ID_{t+1} \mid S_{1:t})$ 表示基于历史序列 $S_{1:t}$ 生成稀疏ID $ID_{t+1}$ 的概率,用于捕捉下一个物品的类别本质;$P(v_{t+1} \mid ID_{t+1}, S_{1:t})$ 表示在给定稀疏ID $ID_{t+1}$ 和历史序列 $S_{1:t}$ 的情况下生成稠密向量 $v_{t+1}$ 的概率,用于捕捉下一个物品的细粒度细节。
这种分解使 COBRA 能够同时利用稀疏 ID 提供的类别信息和稠密向量捕捉的细粒度细节。
7.2.2、基于统一生成模型的序列建模
在序列建模中,采用基于 Transformer 架构的统一生成模型,以有效捕捉用户-物品交互中的序列依赖关系。该 Transformer 接收级联表征的输入序列,其中每个物品由其稀疏 ID 和稠密向量共同表示。
稀疏 ID 嵌入:稀疏 ID(记为 $ID_t$)通过嵌入层转换到稠密向量空间:$e_t = \text{Embed}(ID_t)$。该嵌入 $e_t$ 与稠密向量 $v_t$ 拼接,形成模型在每个时间步的输入:
\[h_t = [e_t; v_t] \tag{2}\]Transformer 建模:COBRA 的 Transformer 解码器模型包含多个层,每层均具备自注意力机制和前馈网络。如上图上半部分所示,解码器的输入序列由级联表征组成。为增强对序列和上下文信息的建模,这些表征还会附加物品位置嵌入和类型嵌入。为简洁起见,后续章节的数学公式将聚焦于级联序列表征,省略位置嵌入和类型嵌入的显式符号。解码器处理这种增强后的输入,生成用于预测后续稀疏 ID 和稠密向量的上下文表征。
稀疏 ID 预测:给定历史交互序列 $S_{1:t}$,为预测稀疏ID $ID_{t+1}$,Transformer的输入序列为:
\[\begin{align*} S_{1:t} &= [h_1, h_2, \ldots, h_t] \\ &= [e_1, v_1, e_2, v_2, \ldots, e_t, v_t] \tag{3} \end{align*}\]其中,每个 $h_i$ 是第 $i$ 个物品的稀疏 ID 嵌入与稠密向量的拼接。Transformer 处理该序列以生成上下文表征,进而用于预测下一个稀疏 ID 和稠密向量。具体而言,Transformer 解码器处理序列 $S_{1:t}$,输出向量序列 $y_t = \text{TransformerDecoder}(S_{1:t})$。稀疏 ID 预测的 logit 由下式得到:
\[z_{t+1} = \text{SparseHead}(y_t) \tag{4}\]其中,$z_{t+1}$ 表示预测稀疏 ID $ID_{t+1}$ 的 logit。
稠密向量预测:为预测稠密向量 $v_{t+1}$,Transformer 的输入序列为:
\[\begin{align*} \bar{S}_{1:t} &= [S_{1:t}, e_{t+1}] \\ &= [e_1, v_1, e_2, v_2, \ldots, e_t, v_t, e_{t+1}] \tag{5} \end{align*}\]Transformer 解码器处理 $\bar{S}_{1:t}$,输出预测的稠密向量:
\[\hat{v}_{t+1} = \text{TransformerDecoder}(\bar{S}_{1:t}) \tag{6}\]7.3、端到端训练
在 COBRA 中,端到端训练过程旨在联合优化稀疏表征和稠密表征的预测。训练过程由一个复合损失函数主导,该函数融合了稀疏 ID 预测损失和稠密向量预测损失。
稀疏 ID 预测损失(记为 \(\mathcal{L}_{\text{sparse}}\))确保模型能够基于历史序列 $S_{1:t}$ 准确预测下一个稀疏 ID:
\[\mathcal{L}_{\text{sparse}} = -\sum_{t=1}^{T-1} \log \left( \frac{\exp\left(z_{t+1}^{ID_{t+1}}\right)}{\sum_{j=1}^{C} \exp\left(z_{t+1}^{j}\right)} \right) \tag{7}\]其中:
- $T$ 为历史序列长度;
- $ID_{t+1}$ 是时间步 $t+1$ 交互物品对应的稀疏 ID;
- $z_{t+1}^{ID_{t+1}}$ 是 Transformer 解码器生成的、时间步 $t+1$ 真实稀疏 ID $ID_{t+1}$ 的预测 logit;
- $C$ 表示所有稀疏 ID 的集合。
稠密向量预测损失($\mathcal{L}_{\text{dense}}$)侧重于优化稠密向量,使其能够区分相似和不相似的物品。该损失定义为:
\[\mathcal{L}_{\text{dense}} = -\sum_{t=1}^{T-1} \log \left( \frac{\exp\left(\cos\left(\hat{v}_{t+1} \cdot v_{t+1}\right)\right)}{\sum_{\text{item}_j \in \text{Batch}} \exp\left(\cos\left(\hat{v}_{t+1}, v_{\text{item}_j}\right)\right)} \right) \tag{8}\]其中:
- $\hat{v}_{t+1}$ 是预测的稠密向量;
- $v_{t+1}$ 是正样本物品的真实稠密向量;
- $v_j$ 表示批次内其他物品的稠密向量;
- \(\cos\left(\hat{v}_{t+1} \cdot v_{t+1}\right)\) 表示预测稠密向量与真实稠密向量的余弦相似度——余弦相似度越高,表明向量方向越接近,这是稠密向量准确预测的理想结果。
稠密向量由端到端可训练的编码器 $\text{Encoder}$ 生成,该编码器在训练过程中被一同优化,确保稠密向量能动态调整以适应推荐任务的特定需求。
总体损失函数公式为:
\[\mathcal{L} = \mathcal{L}_{\text{sparse}} + \mathcal{L}_{\text{dense}} \tag{9}\]这种双目标损失函数实现了平衡的优化过程,使模型能在稀疏 ID 的引导下动态优化稠密向量。这种端到端训练方法同时捕捉高层语义和特征级信息,通过联合优化稀疏表征和稠密表征,实现更优性能。
7.4、从粗到细的生成过程
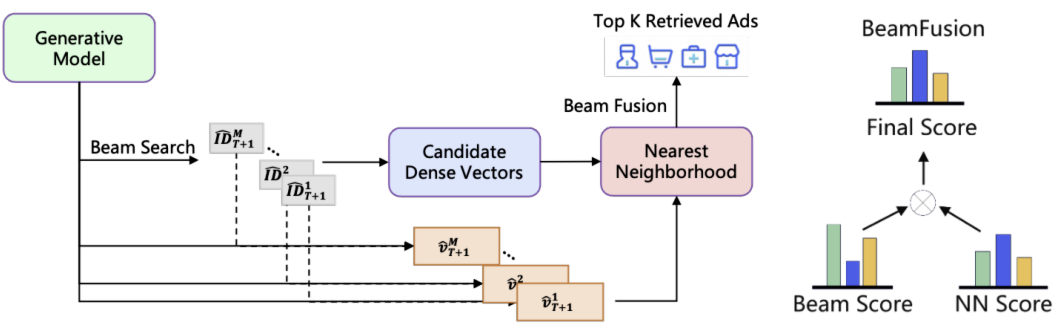
在推理阶段,COBRA 实现从粗到细的生成流程,包括稀疏 ID 的依次生成以及稠密向量的级联式优化,如图所示。COBRA 的从粗到细生成过程旨在同时捕捉用户-物品交互的类别本质和细粒度细节,该过程包含两个主要阶段:
7.4.1、稀疏 ID 生成
给定用户序列 $S_{1:T}$,利用 Transformer 解码器建模的 ID 概率分布 \(\hat{ID}_{T+1} \sim P(i_{T+1} \mid S_{1:T})\),并采用束搜索(BeamSearch)算法得到排名前 $M$ 的 ID。公式如下:
\[\left\{ \hat{ID}_{T+1}^k \right\}_{k=1}^M = \text{BeamSearch}\left( \text{TransformerDecoder}(S_{1:T}), M \right) \tag{10}\]其中,\(k \in \{1, 2, \ldots, M\}\)。每个生成的 ID 都关联一个束得分 $\phi_{\hat{ID}_{T+1}^k}$。
7.4.2、稠密向量优化
每个生成的稀疏 ID \(\hat{ID}_{T+1}^k\) 先被转换为嵌入,再附加到之前的级联序列嵌入 $S_{1:T}$ 中,随后生成对应的稠密向量 \(\hat{v}_{T+1}^k\):
\[\hat{v}_{T+1}^k = \text{TransformerDecoder}\left( \left[ S_{1:T}, \text{Embed}(\hat{ID}_{T+1}^k) \right] \right) \tag{11}\]之后,采用近似最近邻(ANN)搜索检索排名前 $N$ 的候选物品:
\[A_k = \text{ANN}\left( \hat{ID}_{T+1}^k, C(\hat{ID}_{T+1}^k), N \right) \tag{12}\]其中,\(C(\hat{ID}_{T+1}^k)\) 是与稀疏 ID \(\hat{ID}_{T+1}^k\) 关联的候选物品集合,$N$ 表示要检索的顶级物品数量。
7.4.3、束融合(BeamFusion)机制
为在精确性和多样性之间取得平衡,COBRA 为每个稀疏 ID 对应的物品设计了一个全局可比分数。该分数既能反映不同稀疏 ID 之间的差异,也能体现同一稀疏 ID 下物品的细粒度差异。为此,COBRA 提出束融合机制:
\[\Phi\left( \hat{v}_{T+1}^k, \hat{ID}_{T+1}^k, a \right) = \text{Softmax}\left( \tau \phi_{\hat{ID}_{T+1}^k} \right) \times \text{Softmax}\left( \psi \cos\left( \hat{v}_{T+1}^k, a \right) \right) \tag{13}\]其中,$a$ 表示候选物品,$\tau$ 和 $\psi$ 是系数,$\phi_{\hat{ID}_{T+1}^k}$ 是束搜索过程中得到的束得分。
最后,基于物品的束融合得分对所有候选物品排序,并选择排名前 $K$ 的物品作为最终推荐结果:
\[R = \text{TopK}\left( \bigcup_{k=1}^M A_k, \Phi, K \right) \tag{14}\]其中,$R$ 表示最终推荐集合,$\text{TopK}$ 表示选择束融合得分最高的前 $K$ 个物品的操作。
8、美团:MTGR
MTGR:
结合了 DLRM 和 GRM 的优势,保留了 DLRM 的所有特性(包括交叉特征),同时具备 GRM 出色的可扩展性
提出了组层归一化(Group-Layer Normalization)和动态掩码策略,以实现更优性能
基于 TorchRec 的 MTGR 训练框架上进行了系统性优化,提升了训练性能
经典的 DLRM(深度学习推荐模型)结构通常包含多种输入,例如上下文(如时间、地点)、用户画像(如性别、年龄)、用户行为序列,以及带有诸多交叉特征的目标物品。排序模型中两个尤为重要的模块是行为序列处理和特征交互学习。
- 行为序列模块:通常采用目标注意力机制,捕捉用户历史行为与待预测物品之间的相似度
- 特征交互模块:用于捕捉包括用户和物品在内的不同特征之间的交互,以生成最终预测结果
基于 DLRM 中不同的规模化模块,存在两种截然不同的方法:
-
交叉模块规模化,即对整合用户和物品信息的特征交互模块进行扩展
-
用户模块规模化,仅对用户部分进行扩展,这种方法更利于推理
与 DLRM 相对应的是 GRM(生成式推荐模型)。如 Meta 通过 HSTU 验证了规模化定律,模型参数可扩展至万亿级;OneRec 使用语义编码替代传统 ID 表征,将 DPO 优化与基于 Transformer 的框架相结合,用统一的生成模型替代级联学习框架。
8.1、数据和特征
传统上,对于一个用户及对应的 $K$ 个候选物品,用户与第 $i$ 个候选物品组成的第 $i$ 个样本可表示为 $D_i = [U, \overrightarrow{S}, \overrightarrow{R}, C_i, I_i]$。具体而言:
- $U = [U_1, \ldots, U_{N_U}]$ 表示用户的画像特征($U_i$),如年龄、性别等。每个特征 $U_i$ 是一个标量,$N_U$ 表示所用特征的数量
- $\overrightarrow{S} = [S_1, \ldots, S_{N_S}]$ 包含用户历史交互过的物品序列。$S_i = [s_1, \ldots, s_{N_s}]$ 中的每个元素代表一个物品,由选定的特征(如物品ID、标签、平均点击率等)组成
- 与 $\overrightarrow{S}$ 类似,$\overrightarrow{R}$ 记录了当前请求前几小时或一天内的最近交互,用于表征用户的实时行为和偏好,其特征与 $\overrightarrow{S}$ 一致
- $C = [C_1, \ldots, C_{N_C}]$ 包含用户与候选物品之间的交叉特征。
- $I = [I_1, \ldots, I_{N_I}]$ 包含候选物品自身的特征,如物品 ID、标签、品牌等。$I$ 与候选物品相关,且在不同用户间共享。
8.2、推荐系统中的排序模型
对于输入样本 $D$,传统推荐系统会独立处理每个样本:首先对 $D$ 中的特征进行嵌入,将样本转换为稠密表征。具体来说:
- $U$、$C$、$I$ 中的特征经嵌入后,分别拼接为 \(\text{Emb}_U \in \mathbb{R}^{K \times d_U}\)、\(\text{Emb}_C \in \mathbb{R}^{K \times d_C}\) 和 \(\text{Emb}_I \in \mathbb{R}^{K \times d_I}\)
- 对于 $\overrightarrow{S}$ 中的物品 $S_i$,其特征经嵌入后拼接为 \(\text{Emb}_{S_i} \in \mathbb{R}^{d_s}\);$\overrightarrow{S}$ 中的所有物品在另一维度拼接,得到 \(\text{Emb}_{\overrightarrow{S}} \in \mathbb{R}^{N_{\overrightarrow{S}} \times d_s}\)
为提取历史交互物品与候选物品之间的用户兴趣,通常采用目标注意力机制 —— 以目标物品为查询(query),序列特征为键(key)/ 值(value)。形式化表示为:
\[\text{Feat}_{\overrightarrow{S}} = \text{Attention}(\text{Emb}_I, \text{Emb}_{\overrightarrow{S}}, \text{Emb}_{\overrightarrow{S}}) \in \mathbb{R}^{K \times d_S} \tag{1}\]式(1)根据 $I$ 对 $\overrightarrow{S}$ 进行聚合。最后,$D$ 中所有嵌入并处理后的特征拼接为:
\[\text{Feat}_D = [\text{Emb}_U, \text{Feat}_{\overrightarrow{S}}, \text{Feat}_{\overrightarrow{R}}, \text{Emb}_C, \text{Emb}_I] \in \mathbb{R}^{K \times (d_U + d_S + d_R + d_C + d_I)} \tag{2}\]$\text{Feat}_D$ 被输入多层感知机(MLP),输出每个样本的 logit —— 训练时用于模型学习,推理时用于排序。
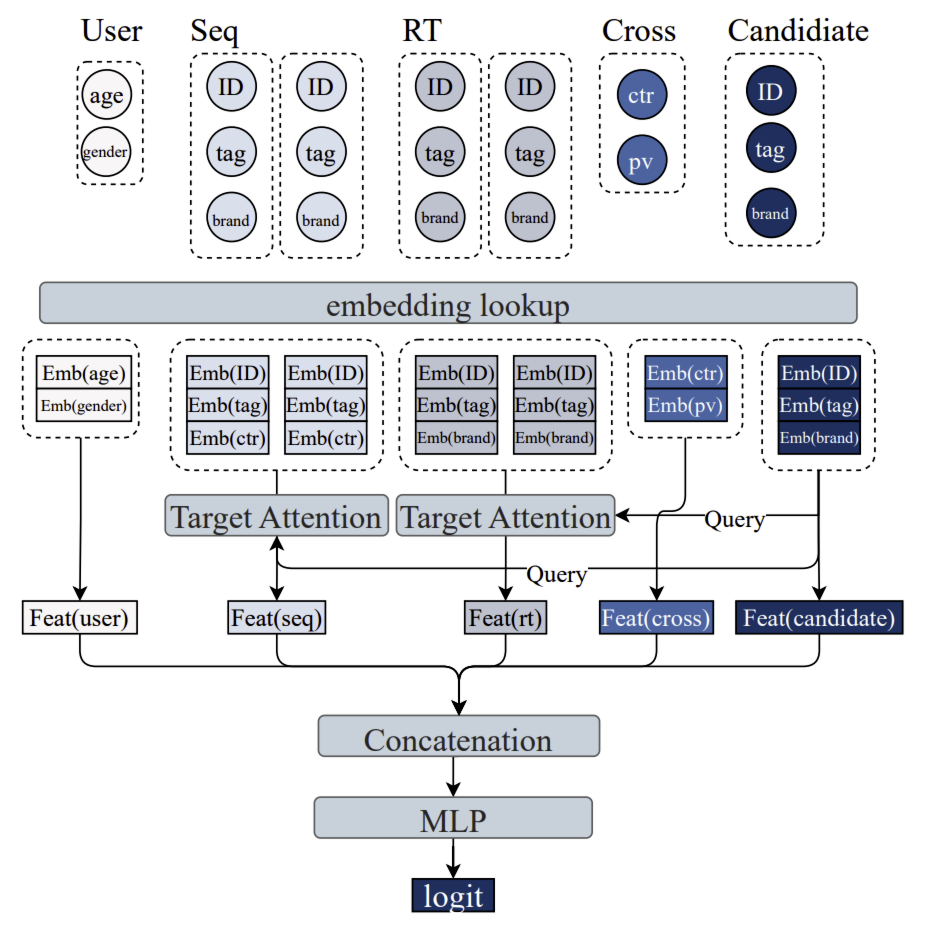
如上图呈现了传统排序模型下简化的数据组织和工作流程:这些特征首先经过嵌入处理,主要嵌入特征通过不同方法进行加工;最终,经过处理的特征被拼接在一起,由多层感知机(MLP)进行特征交互处理,为每个候选物品生成最终的 logit。
8.3、推荐系统中的规模化困境
模型规模化已成为提升排序性能的常用方法。通常,模型规模化旨在扩展用户模块和交叉模块中的参数:
用户模块处理包括序列特征在内的用户特征,生成与用户相关的表征。扩展用户模块能得到更优的用户表征;此外,由于用户是共享的,且一次推理即可适用于所有候选物品,因此用户模块的高推理成本不会导致系统过载。但仅扩展用户模块无法直接促进用户与物品间的特征交互。
相反,另一种方法趋势是扩展交叉模块(即特征拼接后的特征交互 MLP)。这类方法通过更关注用户与候选物品间的交互来增强排序能力。然而,由于交叉模块需为每个候选物品单独推理,计算量会随候选物品数量线性增长,导致系统延迟过高,难以接受。
传统推荐系统的规模化困境催生了新的规模化方法 —— 需要一种能高效实现用户与候选物品特征交互,同时推理成本随候选物品数量呈次线性增长的方案。
8.4、MTGR 的数据重组织与架构
8.4.1、面向训练与推理效率的用户样本聚合
与特征分类相比,对于候选集中的第 $i$ 个样本,MTGR 将特征组织为 $D_i = [U, \overrightarrow{S}, \overrightarrow{R}, [C_i, I_i]]$。具体而言,交叉特征 $C$ 被整合为候选物品的物品特征一部分。在 MTGR 中,训练时候选物品按用户在特定窗口内聚合,推理时按请求聚合。由于聚合针对同一用户,聚合后的样本可复用相同的用户表征($U, \overrightarrow{S}, \overrightarrow{R}$)。其中,$\overrightarrow{R}$ 按交互时间顺序排列用户在另一个特定窗口内的所有实时交互物品。
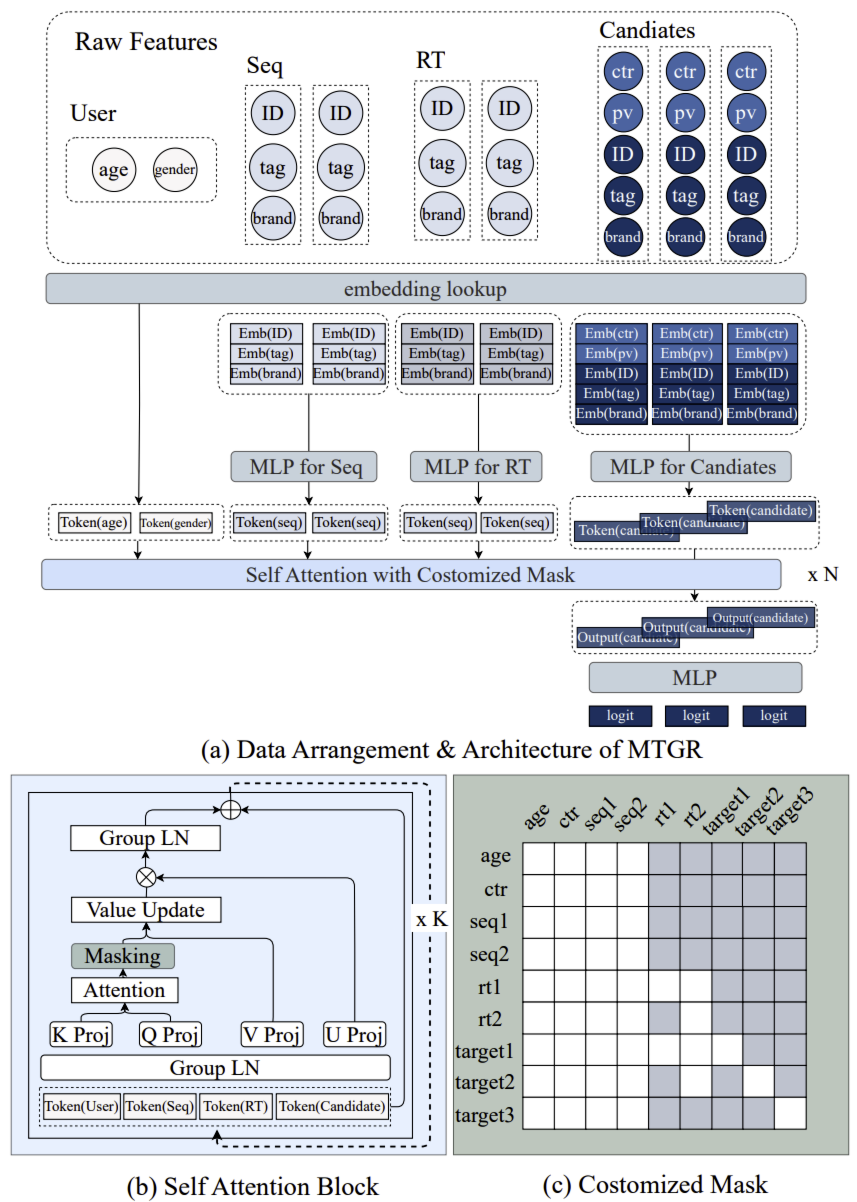
上图展示了聚合过程:与仅预测单个候选物品不同,图(a)将 3 个物品聚合到一个样本中,复用相同的用户表征。形式上,这形成了同一用户的特征表征:
\[D = [U, \overrightarrow{S}, \overrightarrow{R}, [C, I]_1, \ldots, [C, I]_K] \tag{3}\]通过将候选物品聚合到单个样本中,MTGR 只需一次计算即可生成所有候选物品的得分,大幅节省资源。具体而言,用户聚合过程将训练样本量从 “所有候选物品数量” 降至 “所有用户数量”;推理时,同一请求中的候选物品按上述方式分组,MTGR 只需一次推理即可完成所有候选物品的排序,而非按候选物品数量多次推理。这种聚合规避了推理成本对候选物品数量的依赖,为模型规模化提供了可能和潜力。
式(3)是标量特征与序列特征的组合。为统一输入格式,MTGR 将特征和序列转换为 token:
- 对于 $U$ 中的标量特征,每个特征自然转换为单独的 token,维度为 \(\text{Feat}_U \in \mathbb{R}^{N_U \times d_{\text{model}}}\),其中 $d_{\text{model}}$ 是所有 token 的统一维度
- 对于 $\overrightarrow{S}$ 和 $\overrightarrow{R}$ 的序列特征,每个物品 $S$ 被视为一个 token。$S$ 中的特征先经嵌入并拼接,再通过 MLP 模块统一维度,形式上为 \(\text{Feat}_{S_i} = \text{MLP}(\text{Concat}(\text{Emb}_S)) \in \mathbb{R}^{d_{\text{model}}}\);序列中所有 $S$ 的特征在另一维度拼接,得到 \(\text{Feat}_{\overrightarrow{S}} \in \mathbb{R}^{N_{\overrightarrow{S}} \times d_{\text{model}}}\)。
类似地,候选集中的每个物品 $I$ 被视为一个 token。候选物品的特征经嵌入并拼接后,通过另一个 MLP 转换为统一维度;所有候选物品拼接为一系列 token:
\[\text{Feat}_I = \text{Concat}(\text{MLP}(\text{Concat}(\text{Emb}_{C_i}, \text{Emb}_{I_i}))) \in \mathbb{R}^{N_I}\]最后,来自 $U, \overrightarrow{S}, \overrightarrow{R}, \text{Feat}_I$ 的 token 拼接为一个长序列 token:
\[\begin{align*} \text{Feat}_D &= \text{Concat}([\text{Feat}_U, \text{Feat}_{\overrightarrow{S}}, \text{Feat}_{\overrightarrow{R}}, \text{Feat}_I]) \tag{4} \\ &\in \mathbb{R}^{(N_U + N_{\overrightarrow{S}} + N_{\overrightarrow{R}} + N_I) \times d_{\text{model}}} \end{align*}\]User Profile Token: 用户画像中每个原子特征独立形成 1 个 Token
行为序列 Token: 对用户历史每一次行为,取对应 item ID Emb 与其多种 side info Emb(如 tag、品牌等)按固定顺序拼接,经非线性映射压缩成统一维度,得到 1 个行为 Token。
曝光候选 Token: 对当前请求内每个待排序曝光,拼接 item ID Emb、side info Emb、与该候选相关的交叉特征 Emb、时空/上下文特征(用户当前请求的场景信息,如场景,时间,地点等)后,输入同构 MLP 得到 1 个候选 Token
8.4.2、统一 HSTU 编码器
来自同一用户的样本被聚合为 token 序列,这自然适合用自注意力机制处理。受 HSTU 启发,MTGR 采用 stacks of self-attention 层和 encoder-only 架构进行建模。
与 LLM 类似,输入 token 序列按层处理。如上图所示,在自注意力块中,输入序列 $X$ 首先通过 Group Layer Norm 进行归一化——同一领域的特征(例如 $U$)构成一个组,Group Layer Norm 确保自注意力计算前不同领域的 token 具有相似的分布,并对齐不同领域的语义空间,得到 $\tilde{X} = \text{GroupLN}(X)$。归一化后的输入随后被投影到 4 种不同的表征:$K, Q, V, U = \text{MLP}_{K/Q/V/U}(\tilde{X})$。
$Q, K, V, U$ 用于结合 silu 非线性激活函数计算多头注意力,主要注意力会除以输入特征的总长度作为平均因子。接着,在注意力得分上施加定制化掩码($M$),并利用投影后的 $V$ 进行值更新:
\[\tilde{V} = \frac{\text{silu}(K^T Q)}{(N_U + N_{\overrightarrow{S}} + N_{\overrightarrow{R}} + N_I)} \times M \times V \tag{5}\]将投影后的 $U$ 与更新后的 $\tilde{V}$ 进行点积,然后应用另一轮 Group Layer Norm,最后添加残差模块并在其上方设置另一个 MLP:
\[X = \text{MLP}(\text{GroupLN}(\tilde{V} \odot U)) + X \tag{6}\]动态掩码利用因果掩码进行序列建模,但这种方式在 MTGR 中并未带来显著提升。此外,由于 $\overrightarrow{R}$ 记录的是用户最近的交互,其时间可能与样本聚合窗口重合,在 MTGR 中使用简单的因果掩码可能导致信息泄露。例如,晚间的交互不应被暴露给下午的候选物品,但这些信息可能被聚合到同一个样本中。这种困境需要一种灵活且高效的掩码策略。
在 MTGR 中,$U$、$\overrightarrow{S}$ 被视为静态的(下文称 $U$、$\overrightarrow{S}$ 为 “静态序列”),因为其信息来自聚合窗口之前,不会导致因果错误;$\overrightarrow{R}$ 是动态的,因为它实时逐步纳入用户的交互(称 $\overrightarrow{S}$ 为 “动态序列”)。MTGR 对静态序列采用全注意力,对 $\overrightarrow{R}$ 采用带动态掩码的自回归,对候选物品间采用对角线掩码。具体而言,MTGR 的掩码设置遵循 3 条规则:
- 静态序列对所有 token 可见;
- 动态序列的可见性遵循因果关系,每个 token 仅对后续出现的 token(包括候选物品 token)可见;
- 候选物品 token($C, I$)仅对自身可见。
上图(c)展示了动态掩码的一个示例:“age”,“ctr” 代表来自 $U$ 的特征 token;“seq1”,“seq2”代表 $\overrightarrow{S}$;“rt1”,“rt2” 代表 $\overrightarrow{R}$;“target1”-“target3” 代表候选物品。行中的白色块表示特定 token 能够使用其他 token 的信息,列表示该 token 是否对其他 token 可见。
$U$ 和 $S$ 采用全注意力,因此从 “age” 到 “seq2” 形成白色方块。对于 “rt1” 到 “rt2”,假设 “rt1” 晚于 “rt2” 出现,因此 “rt1” 到 “rt2” 形成一个上三角白色块的小方块,意味着 “rt1” 能够使用 “rt2” 的信息,而 “rt1” 对 “rt2” 不可见。此外,假设 “target2” 和 “target3” 早于 “rt1” 出现,因此 “rt1” 对它们不可见;“rt2” 早于 “target1” 和 “target2”,但晚于 “target3”,因此 “rt2” 对早于所有 “rt” 的 “target3” 不可见,导致 “target3” 无法使用 “rt” 的信息。
8.5、训练系统
MTGR 不再沿用先前基于 TensorFlow 的训练框架,而是选择在 PyTorch 生态系统中重构训练框架。
动态哈希表:TorchRec 采用固定大小的表处理稀疏嵌入,这并不适用于大规模工业流训练场景。首先,一旦静态表达到预设容量,就无法为新用户和新物品实时分配额外的嵌入;此时即便使用某些默认嵌入或采用淘汰策略移除 “旧” ID,也会导致模型精度下降。其次,静态表通常需要预分配超过实际需求的容量以防止 ID 溢出,这不可避免地造成内存利用效率低下。
MTGR 实现了一种基于哈希的高性能嵌入表,在训练过程中为稀疏 ID 动态分配空间。MTGR 为哈希表采用解耦架构,将键(key)和值(value)的存储分离到不同结构中:键结构维护一个轻量级映射表,包含键及对应的嵌入向量指针;值结构存储嵌入向量及淘汰策略所需的辅助元数据(如计数器、时间戳)。这种双结构设计实现了两个关键目标:
(1)仅通过复制紧凑的键结构(而非庞大的嵌入数据)实现动态容量扩展;
(2)通过将键存储在紧凑的内存布局中优化键扫描效率,同时适应可能稀疏的键分布。
嵌入查询:嵌入查询过程采用全到全(All-to-all)通信进行跨设备嵌入交换。MTGR 为了减少 ID 通信前后的冗余,采用两阶段 ID 去重操作,在 ID 通信前后分别对 ID 进行去重,避免设备间重复的嵌入传输。MTGR 设计了特征配置接口实现自动表合并,这能减少嵌入查询算子的数量,从而加快查询过程。
负载均衡:在推荐系统中,用户行为序列通常呈现长尾分布 —— 仅有少数用户拥有长序列,而大多数用户的序列较短。这导致在固定批大小(BS)下训练时出现显著的计算负载不均衡。常见解决方案是采用序列打包技术,将多个短序列合并为一个长序列;但这种方法需要仔细调整掩码以防止不同序列在注意力计算中相互干扰,实现成本较高。
MTGR 的直接解决方案是引入动态批大小(dynamic BS):每个 GPU 的本地批大小根据输入数据的实际序列长度调整,确保计算负载相近。此外调整了梯度聚合策略,根据每个 GPU 的批大小对其梯度进行加权,以保持与固定批大小一致的计算逻辑。
其他优化:为进一步提升训练效率,MTGR 通过流水线技术最大化并行性,使用三个流:复制流、分发流和计算流。具体而言,复制流将输入数据从 CPU 加载到 GPU,分发流基于 ID 执行表查询,计算流处理前向计算和反向更新。例如,当计算流执行批次 T 的前向和反向传播时,复制流可并发加载批次 T+1 以掩盖 I/O 延迟;在完成批次 T 的反向更新后,分发流立即启动批次 T+1 的表查询和通信。
此外,MTGR 采用 bf16 混合精度训练,并开发了基于 Cutlass 的定制化注意力核(类似 FlashAttention)以加速训练过程。
9、小红书:NoteLLM-2
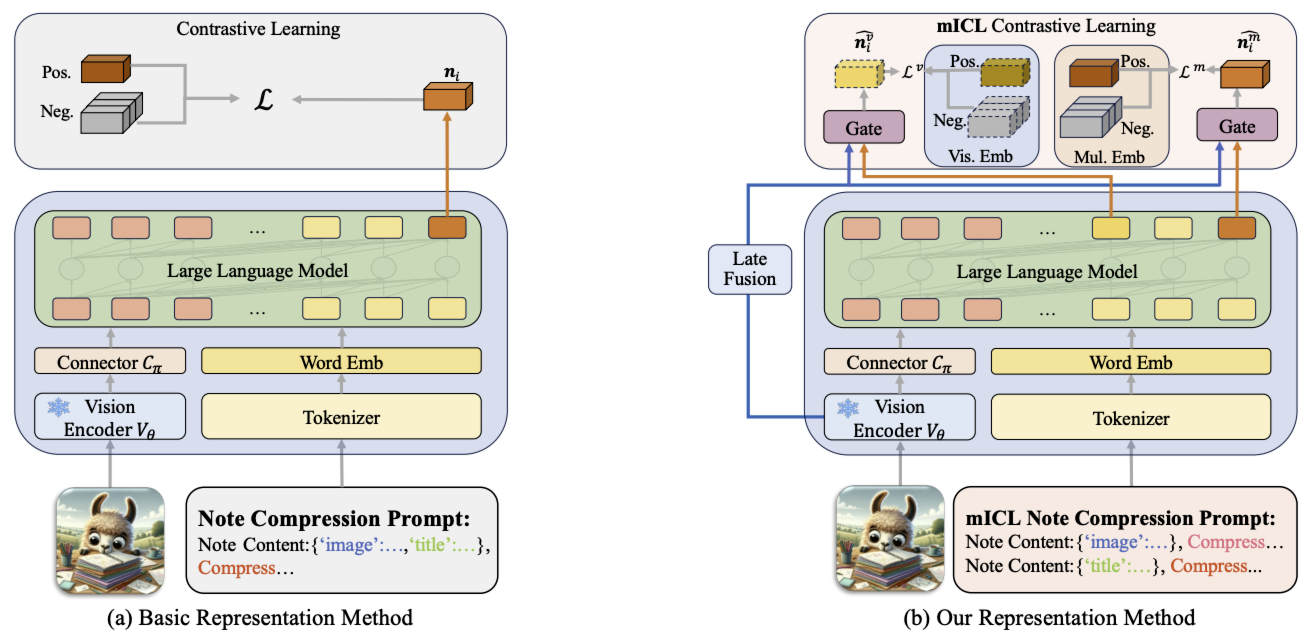
适用于多模态任务的 NoteLLM-2:
- 多模态上下文学习(mICL):多模态内容拆分为视觉与文本两路,分别压缩为模态压缩词,在批次内进行同模态对比学习
- 晚期融合机制(late fusion):保留早期融合(将视觉特征映射到 LLM 的文本特征空间,并通过 LLM 实现视觉特征与文本嵌入的交互)同时引入晚期融合,采用多模态门控融合机制,将视觉编码器输出的视觉表征与 LLM 输出的表征结合,生成最终的多模态表征
在小红书的场景中,每个物品均代表一条笔记,这类笔记由用户生成,用于表达其生活经历。将笔记集合记为 \(N = \{n_1, n_2, \ldots, n_m\}\)(其中 $m$ 为笔记总数),每条笔记均包含文本信息(包括标题、主题和内容)与图像。第 $i$ 条笔记可表示为 $n_i = (t_i, tp_i, ct_i, v_i)$,其中 $t_i$、$tp_i$、$ct_i$、$v_i$ 分别代表该笔记的标题、主题、内容和图像。
给定一条查询笔记 $n_i$,物品-物品(I2I)推荐系统会根据笔记池 \(N \setminus \{n_i\}\) 中各笔记与查询笔记的多模态内容相似度对其进行排序。该系统的目标是将相关目标笔记优先排序。
NoteLLM-2 采用带有明确单词限制的提示词,将多模态内容压缩为单个嵌入:

在该模板中,<IMG> 是占位符,会被原始图像 $v_i$ 处理后得到的视觉嵌入替换。
整体框架如图(a)所示。该框架首先利用视觉编码器 $V_\theta$,将笔记 $n_i$ 中预处理后的图像 $v_i$ 提取为视觉特征 $Z_v \in \mathbb{R}^{L \times h_v}$(其中 $L$ 为视觉特征长度,$h_v$ 为视觉特征维度,且 $Z_v = V_\theta(v_i)$);随后,连接器 $C_\pi$ 将视觉特征 $Z_v$ 转换到 LLMs 的词嵌入空间,形成视觉嵌入 $E_v \in \mathbb{R}^{L_c \times h_t}$ (其中 $L_c$ 为输入 LLM 的视觉嵌入长度,$h_t$ 为LLM隐藏状态维度,且 $E_v = C_\pi(Z_v)$)。
图像处理完成后,文本提示词被分词为离散索引,进而形成文本词嵌入 $E_t \in \mathbb{R}^{T \times h_t}$(其中 $T$ 为文本 token 长度)。为将视觉嵌入插入到文本嵌入的正确位置,用视觉嵌入 $E_v$ 替换 <IMG> token 位置的词嵌入,得到多模态嵌入 $E_m \in \mathbb{R}^{(L_c + T - 1) \times h_t}$。最后,利用 LLM($LLM_\mu$)处理多模态嵌入,生成最终隐藏状态 $H \in \mathbb{R}^{(L_c + T - 1) \times h_t}$(其中$H = LLM_\mu(E_m)$),并将 $H$ 的最后一个嵌入作为笔记 $n_i$ 的笔记表征 $\boldsymbol{n}_i$。该方法通过 “next token prediction” 的形式,约束 LLM 将多模态内容压缩为单个嵌入。
然而,LLM 是基于语言建模损失训练的,这与表征任务的目标存在显著差异。为弥合这一差距,NoteLLM-2 采用对比学习 —— 一种常用于嵌入训练的技术。具体而言,每个小批次包含 $B$ 个相关笔记对,因此每个小批次共含 $2B$ 条笔记。对于小批次中任意一条笔记 $n_i$($1 \leq i \leq 2B$),将其在同一小批次中的相关笔记记为 $n_i^+$。NoteLLM-2 通过梯度下降最小化以下对比损失:
\[\mathcal{L}(\pi, \mu) = -\frac{1}{2B} \sum_{i=1}^{2B} \log \frac{e^{\text{sim}(\boldsymbol{n}_i, \boldsymbol{n}_i^+) \cdot \tau}}{\sum_{j \in [2B] \setminus \{i\}} e^{\text{sim}(\boldsymbol{n}_i, \boldsymbol{n}_j) \cdot \tau}}\]其中,$\tau$ 为可学习温度参数,\(\text{sim}(a, b) = \frac{a^\top b}{\|a\| \|b\|}\)(即余弦相似度)。$\mathcal{L}(\pi, \mu)$ 表示仅更新连接器 $C_\pi$ 和 LLM($LLM_\mu$),同时冻结视觉编码器 $V_\theta$,以实现更大的批次大小和更优性能。
10、小红书:GenRank
GenRank: 解决生成式排序问题
推荐系统需针对一系列预定义任务进行预测,例如预测用户在面对候选物品时的点击率或预期停留时长。为构建离线实验数据集,从小红书的 “发现页” 信息流中,收集 15 天内的数千亿条物品曝光日志。输入特征分为三类:
- 类别特征:用户 ID、物品 ID、用户历史行为、话题标签(hashtags)等;
- 数值特征:用户年龄、物品发布时间、作者粉丝数等;
- 冻结嵌入向量:多模态物品嵌入向量、基于图的作者嵌入向量等。
通过预定义的边界将数值特征离散化为类别特征;通过嵌入表(embedding tables)将类别特征转换为稠密嵌入向量;由预训练模型提供的冻结嵌入向量则被视为 side information,为其关联的特征提供相关 “先验知识”。
10.1、生成范式中的关键机制
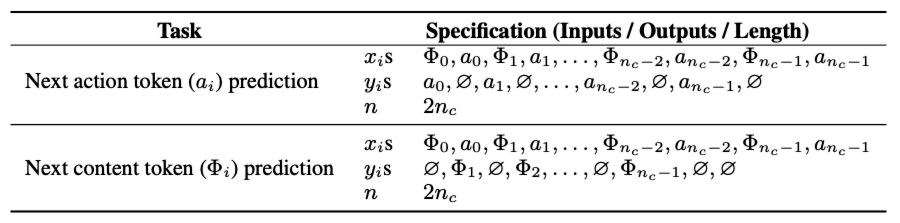
不同于传统范式从历史行为中学习复杂的特征交互,生成式推荐将排序重构为一个序列转导任务(sequential transduction task)。在此背景下,生成式排序在两方面存在显著差异:序列交互方式与训练样本组织形式。
生成式排序中的序列交互方式为自回归(auto-regressive)。HSTU 仅在候选物品对应的位置计算损失,可视为有监督微调,其中用户信息与候选物品作为输入提示。LLMs 在有监督微调阶段采用自回归方式的原因之一,是为保留预训练过程中习得的能力。但生成式排序并不包含预训练阶段,这就引出一个问题:自回归方式对生成式排序而言是否真的必要?
为探究该问题,小红书开展了两组实验。
第一组实验在历史行为对应的位置计算损失(即把历史交互本身也当预测目标做自回归损失,而不是仅把历史当条件输入)。结果显示,即便仅包含少量历史位置,AUC 仍显著下降。将此归因于 “单轮训练问题”(one-epoch issue)—— 即模型从稀疏特征中学习到了错误模式。
第二组实验中,将历史位置处的因果掩码(causal mask)替换为全可见掩码(fully visible mask)。这一修改与 T5 模型的做法类似:在 T5 模型中,注意力掩码(attention mask)会最大化提示语(prompt)内的特征交互。但该修改导致 AUC 显著下降,且随着模型规模增大,下降幅度愈发显著。这些结果表明,自回归方式对生成式排序的有效性至关重要。
传统范式中训练样本的组织形式通常为逐点式(point-wise):即每个训练样本对应一条物品曝光日志。与之相反,生成式排序会将用户在时间上相邻的行为归为单个训练样本。这种组织形式存在两方面潜在优势:
其一,由于同一请求的两条曝光日志在特征(尤其用户特征)上高度重叠,将它们纳入同一批次处理可提升梯度估计的稳定性;
其二,从实践角度考量,在大规模在线分布式训练中,样本的处理顺序并不严格遵循实际时间顺序,这可能导致信息泄露。在此情况下,模型在训练过程中,可能在看到某物品的曝光日志之前,就通过历史行为特征推断出用户对该物品的偏好。而生成式排序的样本组织方式,有助于降低 “先训练后续样本、再训练前期样本” 的风险。
10.2、不同范式下的模块性能对比
小红书选取工业界排序系统中常用的四个重要模块进行对比:用于序列建模的 SIM、用于个性化表征学习的 PP-Net、用于提供先验知识的内容嵌入向量,以及用于多任务学习的 PLE。结果显示,SIM、PP-Net 和 PLE 在两种范式下实现了相近的性能提升,这表明生成式范式与这些模块具有兼容性。
此外,在生成式范式下,内容嵌入向量带来的 AUC 提升幅度超过两倍。这一提升归因于:内容嵌入向量的生成式训练与其在下游任务中的应用之间存在架构一致性,使得其能力能够得到最优利用。
特征工程对工业界推荐系统的性能至关重要。HSTU 提出移除这些特征,理由是生成式推荐模型能够充分表达统计模式。小红书的实验结果表明:尽管大多数特征对生成式架构的增益微乎其微,但部分实时统计特征(尤其是基于时间窗口的特征)在提升性能方面仍表现出显著效果。这些特征为模型提供了直接信号,使生成式架构能够学习复杂模式。
值得注意的是,特征工程所伴随的巨大计算开销,限制了排序模型对大规模候选集的实时处理能力。而生成式架构通过降低对特征工程的需求,解决了这一局限,从而提升了推理可扩展性。此外,键值缓存(KV cache)机制使生成式架构能够随着候选集规模的增大,更高效地实现扩展。随着计算开销的持续降低,未来的系统中,生成式架构有望实现排序阶段与预排序阶段的统一。
10.3、Item-Action 组织
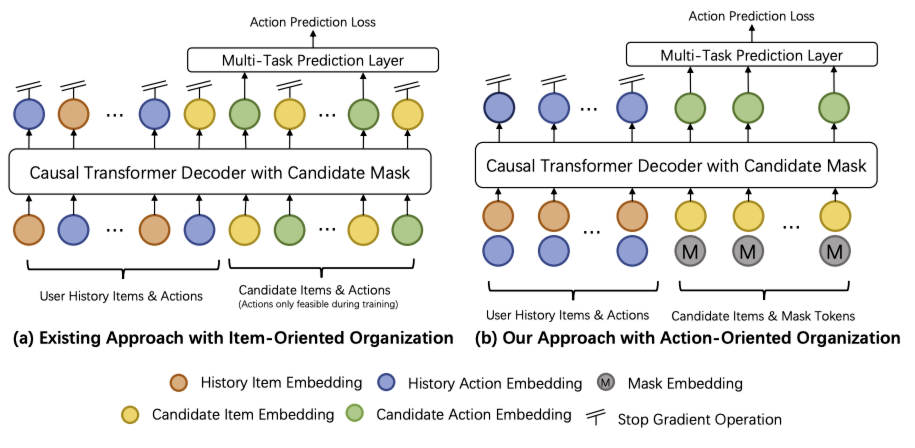
传统的序列推荐方法通常以单个物品为基本单元构建模型,这种组织框架为面向物品的架构(item-oriented architecture)。为使这类方法适配排序任务中 action-aware 的建模形式,HSTU 将 action tokens 视为序列中的一种额外模态。如图所示,它将物品与行为交织在单个序列中,从而使模型能基于上下文序列预测物品或行为。尽管这类方法能在统一框架内支持召回与排序任务,但由于序列长度翻倍,会给排序带来巨大开销。
为解决这一局限,GenRank 提出一种新视角:将物品视为位置信息,重点迭代预测与每个物品相关联的行为 —— 将这种方式称为面向行为的组织方式(action-oriented organization)。在此范式下,如图(b)所示,行为成为序列生成中的基本单元,而物品则作为引导生成过程的上下文信号。该方法聚焦于行为预测,在效率方面具有显著优势:这一设计使注意力机制的输入序列长度缩短一半,进而使注意力计算成本降低 75%,线性投影成本降低 50%。
考虑按时间顺序排列的 $N$ 个用户令牌序列 $x_1, x_2, …, x_N$,其中 $x_i \in X$( $X$ 为物品集合)。对于每个物品 $x_i$,存在一个关联行为 $a_i \in A$($A$ 为行为集合),该行为发生于时间戳 $t_i$。因此,行为序列为 $a_1, a_2, …, a_N$,对应的时间戳序列为 $t_1, t_2, …, t_N$。模型通过学习逼近分布 $p(a_k \mid x_1, a_1, …, x_k)$ 实现建模。
为构建面向行为的生成式排序,每个输入令牌均融合了物品嵌入向量与行为嵌入向量,如图(a)所示。在用户历史序列的每个位置,令牌嵌入向量由物品嵌入向量与行为嵌入向量求和得到,即 $e_i = \phi(x_i) + \phi(a_i)$,其中 $\phi(\cdot)$ 和 $\phi(\cdot)$ 分别表示物品嵌入模块与行为嵌入模块。任务是预测用户对下一个候选物品的行为。为实现这一目标,候选物品的令牌嵌入向量定义为 $e_j = \phi(x_j) + M$,其中 $M$ 为掩码行为嵌入向量(mask action embedding)。需注意,为防止候选物品间的信息泄露,引入了候选掩码(candidate mask),如图(b)右侧所示。
10.4、位置和时间偏差
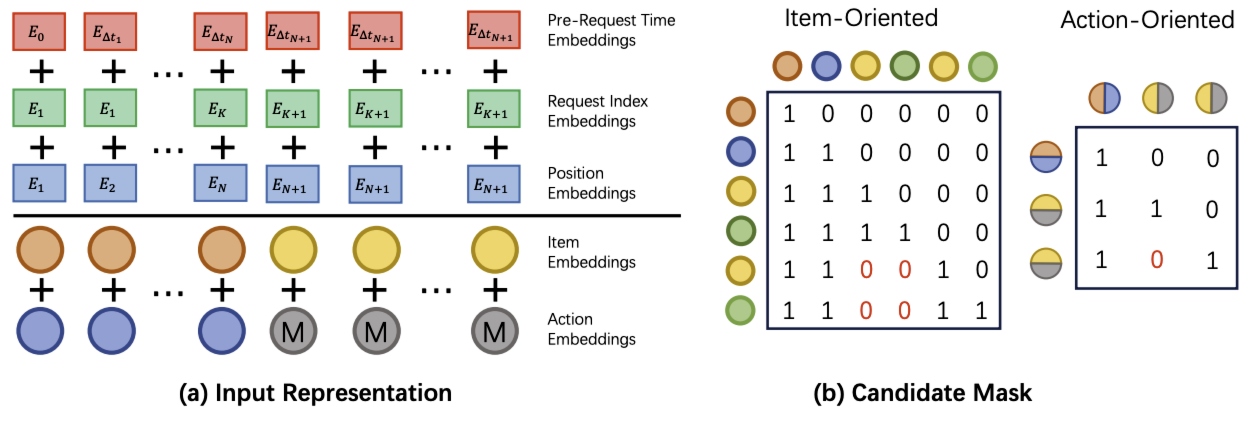
HSTU 采用可学习的相对注意力偏差对位置和时间信息进行编码。尽管该设计对性能至关重要,但也引入了计算瓶颈:注意力偏差的输入输出(I/O)操作随序列长度呈二次方增长,导致上下文窗口扩大时产生巨大开销。
这种低效性促使 GenRank 设计能显著降低系统成本的新型位置与时间偏差。具体而言,小红书提出了一套全面的位置和时间嵌入向量设计方案,仅需线性输入输出操作,包括:
- 位置嵌入向量(Position Embeddings):采用可学习的位置嵌入向量记录物品在用户序列中的索引,记为 $E_{pe,i} = \Omega_{pe}(i)$。为保证训练与推理的一致性,同一请求内的候选物品共享相同位置。
- 请求索引嵌入向量(Request Index Embeddings):实际场景中,用户可能在单次请求内与多个物品产生交互。将属于同一请求的所有物品归为一组,并定义请求索引嵌入向量 $E_{ri,i} = \Omega_{ri}(\mid {t_1, …, t_i} \mid)$,其中 $|\cdot|$ 表示集合的基数(即元素个数)。
- 请求前时间嵌入向量(Pre-Request Time Embeddings):该嵌入向量捕捉每个物品与前一次请求时间之间的分桶后时间差(bucketed time difference),反映用户的活跃程度。具体定义为$E_{rt,i} = \Omega_{rt}(\text{bucket}(t_i - \max_{t_j < t_i} t_j))$。
上述设计在保留位置和时间信息的同时,仅引入极小的训练开销。最终,输入至后续网络的表示为:
\[e^{(p,t)}_i = \phi(x_i) + \Phi(a_i) + E_{pe,i} + E_{ri,i} + E_{rt,i}\]此外,上述位置和时间嵌入向量存在一个关键局限:时间与位置信息之间缺乏交互。为解决这一问题,小红书提出在注意力机制中采用无参数偏差 ALiBi 作为相对位置与时间偏差。
ALiBi 具有两大优势:其一,它会对距离较远的查询-键(query-key)对的注意力分数进行惩罚,且惩罚力度随键行为令牌与查询行为令牌之间距离的增大而增强 —— 该设计更贴合用户兴趣建模的模式;其二,ALiBi 无需参数,即不需要 $O(N^2)$ 的内存访问开销或梯度反向传播。通过将 ALiBi 融合到 FlashAttention 中,仅会产生极小的计算成本。
11、快手:OneSug
OneSug:面向电商查询建议的端到端生成式框架
11.1、查询建议
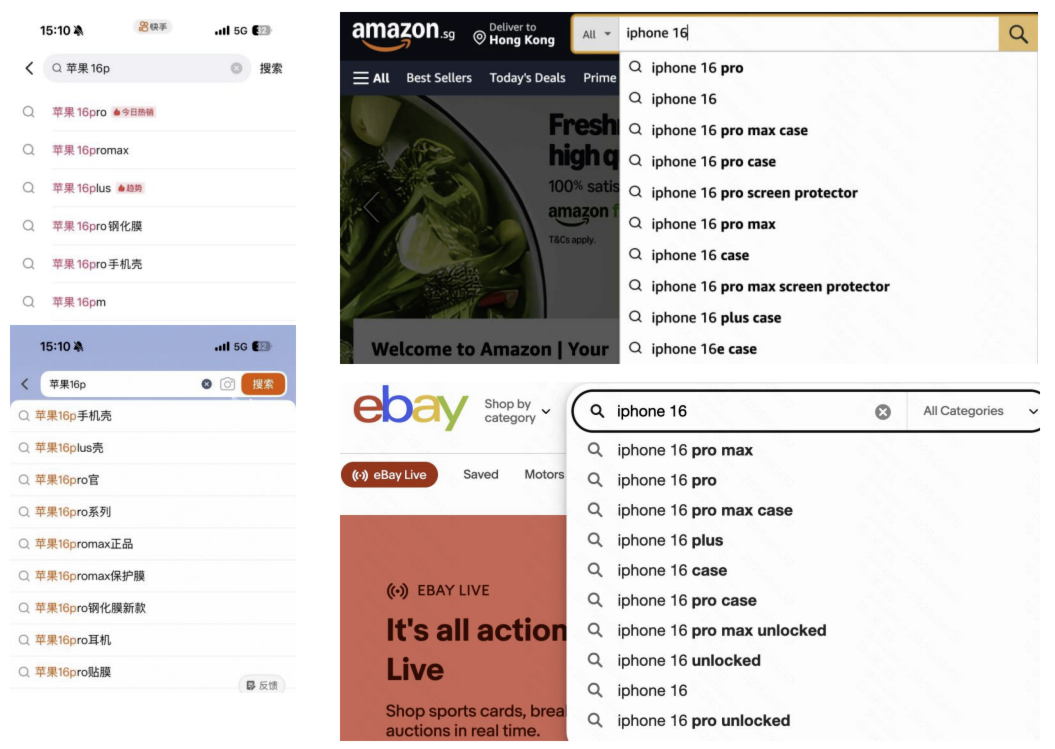
查询建议(Query Suggestion)旨在通过推荐与用户初始输入相关的新查询来提升用户体验。该模块通过提供更具体、更精准的查询推荐,帮助用户定位符合其个性化信息需求的内容,或提供具有相同兴趣的用户最常搜索的关键词,从而减少后续输入操作,提升搜索效率。
举个典型例子:若用户想购买一部新智能手机并输入 “smartphone” 作为查询词,搜索引擎可能会显示各类品牌和型号的智能手机,而用户或许对特定品牌或功能感兴趣。一个实用的查询建议模块应给出诸如 “2025年最佳智能手机” 或 “智能手机性价比排名” 之类的建议,帮助用户缩小搜索范围,找到最符合自身需求的商品。
现有查询建议模块通常会利用存储在查询日志中的历史用户 - 系统交互数据,以及存储在特定流程中的热门搜索趋势词,来细化不同的搜索意图。具体而言,为平衡效率与性能,这些模块通常采用多阶段级联架构(Multi-stage Cascading Architecture, MCA) 。在 MCA 中,用户输入的前缀会依次经过召回、预排序和排序三个阶段,最终向用户展示若干查询建议。每个阶段负责接收前一阶段输出的所有查询,并筛选出排名靠前的候选查询传递至下一阶段。
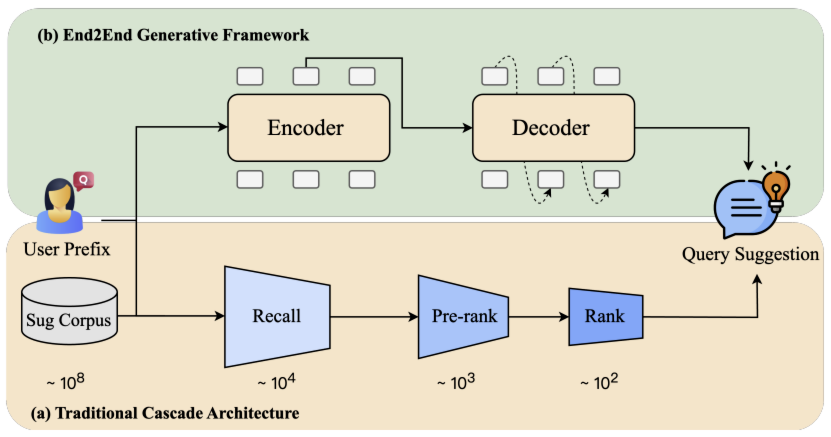
如图所示,召回阶段会对所有候选查询($10^8$ 个)进行检索,预排序阶段仅处理接收的 $10^4$ 个查询,而排序阶段则针对 $10^2$ 个查询进行处理。
然而,对系统响应时间与业务转化平衡的过度追求,导致前序阶段(召回、预排序)只能局限使用轻量级模型,复杂推理仅能在最终的排序阶段进行。这种不一致性使得现有方法存在以下局限:
1)前序阶段的性能决定了后续阶段的性能上限;
2)具有不同优化目标的异构模块可能导致整个级联架构的性能欠佳;
3)现有方法无法为未见过的前缀筛选出有效的查询建议,从而限制了其在长尾会话(long-tail sessions)中的性能。
此类问题同样存在于电商/视频搜索、推荐及广告引擎的级联架构中。为解决这些问题,近年来的研究致力于采用生成式检索(Generative Retrieval, GR)方法替代 MCA 中的部分甚至全部阶段。
通常,GR 模型会被训练为将条目直接映射为基于 ID 或基于字符串的编码,并通过自回归方式生成候选条目的标识。生成式模型丰富的语义知识与强大的推理能力,使其能够更好地捕捉输入的细粒度特征,从而在召回或排序任务上超越传统方法。
其中,OneRec 是代表性工作之一,其通过基于会话的生成方法与迭代式偏好对齐模块替代了完整架构,实现了端到端的视频推荐。尽管该范式前景广阔,但并不适用于查询建议任务:
- 首先,视频推荐属于封闭词汇任务(close-vocabulary task) ,其输入与输出均为特定视频;而查询建议中,用户输入与对应输出均为开放(词汇) 形式;
- 其次,查询建议模块必须考虑前缀与查询之间的相关性,因此需要更细粒度的排序建模,而非基于会话的建模方式。
11.2、生成式框架 OneSug
面向电商查询建议的端到端生成式框架 OneSug 包含以下三个核心组件:
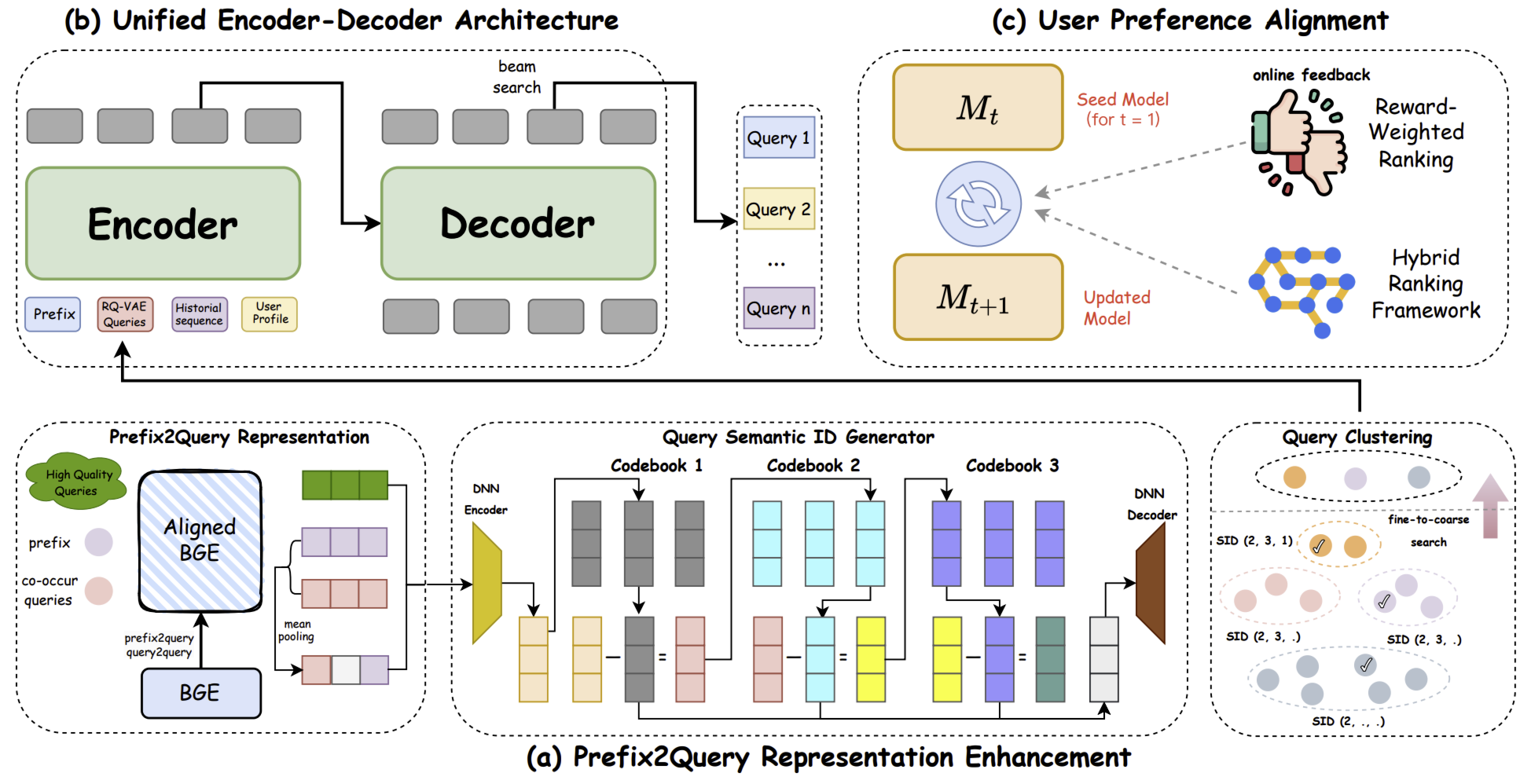
1) Prefix2query 表示增强(PRE)模块
鉴于短前缀(通常仅单个词汇)存在语义模糊问题(例如,“apple” 既可指代水果,也可指代公司),OneSug 尝试利用交互相关和语义相关的查询来增强前缀表示。首先,使用筛选后的<前缀,查询>微调表示模型,以实现内容特征与业务特征的对齐;随后,采用 RQ-VAE 生成层级化的量化语义编码,使每个前缀都能通过编码近似的查询得到增强。该模块不仅能缓解短前缀语义表示不足的问题,还能有效融合语义特征与业务特征;此外,RQ-VAE 的引入可减少推理过程中的大量匹配计算,进一步为生成式模型的实际部署提供便利。
2) 统一的编码器 - 解码器架构
该架构以前缀、相关查询、用户历史交互查询及用户画像为输入,直接输出用户可能感兴趣的查询。这种统一结构设计简洁,能有效避免多阶段级联架构中各阶段优化目标不一致导致的最终结果欠佳问题,因此可直接用于端到端的实际应用部署。
3) 基于奖励加权排序(RWR)策略的用户偏好对齐机制
针对生成式模型,OneSug 设计了这一偏好对齐机制:首先,将用户交互行为划分为六个不同等级,并基于这些等级构建九类正负样本序列;随后,采用直接偏好优化(DPO)方法,根据等级差异为样本分配不同权重,助力模型学习样本间的偏好差异。此外,受传统点击率(CTR)模型启发,将 DPO 从基于成对数据的对比学习扩展至基于列表数据的学习;最终提出一种融合列表级与点级方法的混合排序框架,旨在为生成式模型注入高效的排序能力,确保生成序列的准确性。与迭代偏好对齐(IPA)中仅选择最优和最差样本进行简单采样的方式不同,基于用户交互行为等级差异的奖励加权序列排序,能更有效地捕捉用户对不同查询行为的细微差异,从而提升生成式模型实现精准个性化排序的能力。
OneSug 的输入包含四部分:
1)用户输入前缀,记为 $p$,通常是不完整的查询,例如 “smart” 对应 “智能手机(smartphone)” 的潜在购买意图;
2)收集到的 prefix2query 序列,作为 $p$ 的增强参考,记为 $\mathcal{H}_p = {q_a^1, q_a^2, …, q_a^m}$,其中 $q_a$ 代表来自 RQ-VAE 的查询,$m$ 为 prefix2query 序列的长度;
3)历史搜索查询 $\mathcal{H}_u = {q_h^1, q_h^2, …, q_h^n}$,其中 $q_h$ 代表用户搜索过的查询,$n$ 为行为序列的长度;
4)用户画像信息 $\mathcal{U}$,即平台拟合的人群画像。OneSug 的输出为对应的查询列表 $\mathcal{Q}$。
OneSug 可基于编码器 - 解码器模型(如BART、mT5)或仅解码器模型(如 Qwen2.5)构建。借助这些生成式模型强大的指令跟随能力和内置的电商领域知识,OneSug 有望生成满足用户多样化需求的电商意图查询。在后续描述中,OneSug 记为 $\mathcal{M}$。
11.3、Prefix2Query表示增强
前缀-查询对齐: 鉴于其在各类中文自然语言处理(NLP)任务中具备较强的通用性,选用 BGE 作为初始表示模型。但该模型在电商领域的知识有限,因此需将其与真实的用户 - 前缀 - 查询交互数据相结合。
此外,前缀与查询之间的本质差异会导致表示空间错位,阻碍后续的一致性优化。受 QARM 启发,OneSug 旨在实现表示对齐并注入潜在检索知识,确保 BGE 能反映真实业务特征。具体而言,利用 ItemCF、Swing 等现有检索模型生成高质量的 prefix2query 和 query2query 配对,再筛选出语义相关的配对以提升性能。基于这些高质量配对数据,通过以下流程训练对齐后的 BGE 模型:
\[\begin{aligned} E_{\text{trigger}} &= \text{BGE}\left(T_{\text{trigger}}\right), \\ E_{\text{target}} &= \text{BGE}\left(T_{\text{target}}\right), \\ \mathcal{L}_{\text{align}} &= \text{Batch-Contrastive}\left(E_{\text{trigger}}, E_{\text{target}}\right). \end{aligned} \tag{1}\]其中,$T_{\text{trigger}}$ 和 $T_{\text{target}}$ 分别表示触发查询和目标查询的原始向量,$E_{\text{trigger}}$ 和 $E_{\text{target}}$ 为可学习 BGE 模型生成的对应嵌入向量,$L_{\text{align}}$ 为对齐训练损失。通过优化该损失,可促使 BGE 的语义表示与下游业务特征对齐。
在电商查询建议场景中,用户输入的前缀往往较短(通常仅单个词汇),导致前缀语义表示存在模糊性。为利用语义相关和交互相关的查询丰富这些前缀,OneSug 提出通过前缀 - 查询共现实现前缀表示增强。具体而言,对于给定前缀 $p$,借助对齐后的 BGE 模型,利用高度相关的查询 $q$ 得到增强后的前缀嵌入 $e_p^* \in \mathbb{R}^d$:
\[\begin{aligned} \bar{e}_q^c &= \frac{1}{k}\sum_{i=1}^k e_{q_i}^c, \\ e_p^* &= (1-w) \cdot e_p + w \cdot \bar{e}_q^c \quad \text{where } w \in (0,1), \end{aligned} \tag{2}\]其中,$e_p$ 为原始前缀嵌入,$e_{q_i}^c$ 为与 $p$ 共现的第 $i$ 个查询的嵌入,$\bar{e}_q^c$ 为这些查询嵌入的均值池化结果,$e_p^*$ 为经权重 $w$ 调整后的增强前缀嵌入。在 OneSug 的训练过程中,$w$ 的取值设为 0.5。
层级化量化语义 ID 生成器: 如上图所示,将前缀表示与高质量候选查询对齐后,可收集前缀的对齐嵌入,以及相似度超过特定阈值的相关查询的对齐嵌入。下一阶段将采用 RQ-VAE 生成语义 ID(Semantic IDs),对应的训练目标如下:
\[\begin{aligned} \mathcal{L}(x) &:= \mathcal{L}_{\text{recon}} + \mathcal{L}_{\text{rqvae}}, \\ \mathcal{L}_{\text{recon}} &:= \|x - \hat{x}\|^2, \\ \mathcal{L}_{\text{rqvae}} &:= \sum_{d=0}^{m-1} \| \text{sg}[r_i] - e_{c_i} \|^2 + \beta \| r_i - \text{sg}[e_{c_i}] \|^2, \end{aligned} \tag{3}\]其中,$x$ 和 $\hat{x}$ 分别为 DNN 编码器的输入和解码器的输出,$\text{sg}[\cdot]$ 表示停止梯度(stop-gradient)操作,$r_i$ 为第 $i$ 个残差嵌入,$e_{c_i}$ 为最近中心嵌入的索引。在此过程中,会对中间的 DNN 编码器/解码器及码本(codebooks)进行训练。通过 RQ-VAE 提取前缀的语义 ID 后,通过基于聚类的搜索确定与前缀最相关的前 $k$ 个查询。
搜索过程采用由精到粗的方式:先筛选出具有相同语义 ID 的高质量查询,再选取共享相同码字(codewords)的查询;此外,还会基于多样性和相关性对前 $k$ 个查询进一步筛选。该模块不仅能缓解短前缀语义表示不足的问题,还能有效融合语义特征与转化特征;同时,RQ-VAE 的引入可降低推理过程中匹配任务的计算复杂度,进一步为生成式模型的实际部署提供便利。
11.4、统一的编码器 - 解码器架构
与线上多阶段级联架构不同,OneSug 基于生成式架构,通过束搜索(beam search)直接输出用户最感兴趣的查询。OneSug 模型 $\mathcal{M}$ 的输出可形式化表示为:
\[\mathcal{Q} := \mathcal{M}\left(p, \mathcal{H}_p, \mathcal{H}_u, \mathcal{U}\right) \tag{4}\]该模型采用基于 Transformer 的架构,包含一个对用户历史交互进行建模的编码器,以及一个专门用于查询生成的解码器。
具体而言,编码器利用堆叠的多头自注意力层(multi-head self-attention layers)和前馈层(feed-forward layers)处理 $p$、$\mathcal{H}_u$、$\mathcal{H}_p$ 和 $\mathcal{U}$,生成编码后的历史交互特征 $\mathcal{H}$,可表示为 $\mathcal{H} = \text{Encoder}(p, \mathcal{H}_u, \mathcal{H}_p, \mathcal{U})$。解码器以目标查询的 tokens 为输入,通过自回归方式生成候选查询。
为实现统一训练,在输入序列首位插入起始 token $t_{[\text{CLS}]}$,并在相邻元素之间插入分隔 token $t_{[\text{SEP}]}$,构成编码器的输入:
\[x_u = \{t_{[\text{CLS}]}, p, t_{[\text{SEP}]}, \mathcal{H}_p, t_{[\text{SEP}]}, \mathcal{H}_u, t_{[\text{SEP}]}, \mathcal{U}\} \tag{5}\]OneSug 采用交叉熵损失(cross-entropy loss)对目标查询的 token ID 进行下一个 token 预测。在生成任务上完成一定训练步数后,得到基础模型 $\mathcal{M}_t$。
11.5、用户偏好对齐
11.5.1、奖励加权排序
OneRec 通过提出个性化多任务奖励模型解决用户 - 物品交互稀疏带来的标注难题,而 OneSug 的方案则利用线上搜索系统的反馈作为更易获取的奖励信号来源。具体而言,将搜索系统中的用户交互行为划分为 6 个不同等级,详情如下表所示。
随后为每个等级分配加权奖励分数 $r(x_u, q) = \lambda \cdot e^{p_i}$,其中 $\lambda$ 为基础权重,6 个等级对应的取值依次为 [2.0, 1.5, 1.0, 0.5, 0.2, 0.0],$p_i$ 为同一等级内各交互查询的占比。因此,<前缀,查询>对在同一等级中出现的次数越多,获得的奖励分数越高。需要说明的是,OneSug 未像 OneRec 那样将点击率(CTR)用作奖励模型,不仅因为训练高质量 CTR 模型需要数百甚至数千个特征,还因为线上数据偏差概率较高,不利于后续模型更新的优化。
| 线上反馈指标(Online Feedback) | 说明(Comments) |
|---|---|
| 下单(Order) | 用户通过特定查询完成商品购买 |
| 商品点击(Item Click) | 用户通过特定查询点击商品 |
| 查询点击(Click) | 用户点击特定查询 |
| 展示(Show) | 特定查询在面板中展示 |
| 未展示(Not Show) | 查询存在于召回结果但未展示 |
| 随机(Rand) | 排序候选集中的随机查询 |
将 “下单”、“商品点击”、“查询点击” 作为正样本,“展示”、“未展示”、“随机” 作为负样本,构建 9 类<正样本,负样本>采样对,例如<下单,展示>和<展示,随机>。对于每一对样本,计算用户偏好差异权重值 $rw_{\Delta}$:
其中 $q_w$ 为优势样本(win sample),$q_l$ 为劣势样本(lose sample)。较小的 $rw_{\Delta}$ 值会促使模型区分用户交互行为的细微差异,以及前缀与查询的共现行为。
11.5.2、直接偏好优化
直接偏好优化(DPO)仅依赖成对比较,难以学习不同样本间的绝对可能性,导致缺乏排序能力。在奖励加权排序(RWR)的辅助下,DPO 通过动态调整样本权重获得一定排序能力。为实现泛化,还引入目标奖励边际 $\delta > 0$,确保选中样本的奖励至少比未选中样本高 $\delta$。DPO 损失可按如下方式优化:
\[\begin{array}{r} \mathcal{L}_{\text {pair-wise }}=-\mathbb{E}\left[\log \sigma\left(r w_{\Delta}\left(\max \left(0, \hat{r}_\theta\left(x_u, q_w\right)-\hat{r}_\theta\left(x_u, q_l\right)-\delta\right)\right)\right)\right. \\ \left.+\alpha \log \pi_\theta\left(q_w \mid x_u\right)\right], \end{array} \tag{7}\]其中:
\[\hat{r}_\theta(x_u, q_{w/l}) = \beta \log \frac{\pi_\theta(q_{w/l} \vert x_u)}{\pi_{\text{ref}}(q_{w/l} \vert x_u)} \tag{8}\]\(\hat{r}_\theta(x_u, q_w)\) 和 \(\hat{r}_\theta(x_u, q_l)\) 是由语言模型 $\pi_\theta$ 和参考模型 $\pi_{\text{ref}}$ 隐式定义的奖励。
为避免模型仅迎合奖励模型而牺牲生成质量,引入 $\log \pi_\theta(q_w \vert x_u)$(即有监督微调损失,SFT loss)。此外,通过引入 $rw_{\Delta}$ 为不同样本分配动态权重。
对于难负样本对(如 <查询点击,展示>),选中样本与未选中样本的奖励差异较小,但 $rw_{\Delta}$ 值较大,因此优化函数会扩大 \(\hat{r}_\theta(x_u, q_w)\) 与 \(\hat{r}_\theta(x_u, q_l)\) 的差异,使其大于普通样本对(如<查询点击,随机>)的差异。这样一来,模型就能学习到用户针对同一前缀的交互行为细微差异。最终,在 RWR 模块的作用下,模型的排序能力得到有效提升。
传统 DPO 基于 Bradley-Terry 偏好模型构建,这种训练范式无法充分利用用户偏好数据,且忽略了同一前缀下不同负样本的细微差异,从而阻碍语言模型与用户偏好的对齐。受 S-DPO 启发,OneSug 将用于完整相对排序的传统 Plackett-Luce(PL) 偏好模型推广至适用于部分排序的场景(更符合推荐任务的实际需求)。
具体而言,在偏好学习阶段,不再构建单一<正样本,负样本>对,而是将输入 tokens 与正样本及多个负样本配对,构建更全面的偏好数据集。同时,OneSug 为列表级建模设计了边际损失:通过要求样本间的差异需大于 $\delta$,使模型对训练数据中的微小波动或标签噪声更不敏感。
其中 $Q_l$ 为负样本集合。通过融合列表级偏好对齐与优势样本的对数似然,OneSug 构建了一种用于生成式排序的新型混合范式。
参考文献
- Recommender Systems with Generative Retrieval
- Actions Speak Louder than Words: Trillion-Parameter Sequential Transducers for Generative Recommendations
- OneRec: Unifying Retrieve and Rank with Generative Recommender and Preference Alignment
- OneSug: The Unified End-to-End Generative Framework for E-commerce Query Suggestion
- Sparse Meets Dense: Unified Generative Recommendations with Cascaded Sparse-Dense Representations
- MTGR: Industrial-Scale Generative Recommendation Framework in Meituan
- MTGR:美团外卖生成式推荐Scaling Law落地实践
- Autoregressive Image Generation using Residual Quantization
- HLLM: Enhancing Sequential Recommendations via Hierarchical Large Language Models for Item and User Modeling
- Towards Large-scale Generative Ranking
