本文整合自 参考文献 多篇文章,主要介绍模型并行训练的相关知识
1、模型并行
1.1、并行技术概述
在现代机器学习中,各种并行技术被用于:
- 将超大型模型适配到有限的硬件上
- 显著加速训练,将原本需要一年的训练时间缩短至数小时
我们将首先深入讨论各种 1D 并行技术及其优缺点,然后探讨如何将它们组合成 2D 和 3D 并行技术,以实现更快的训练并支持更大规模的模型。
核心并行方法:
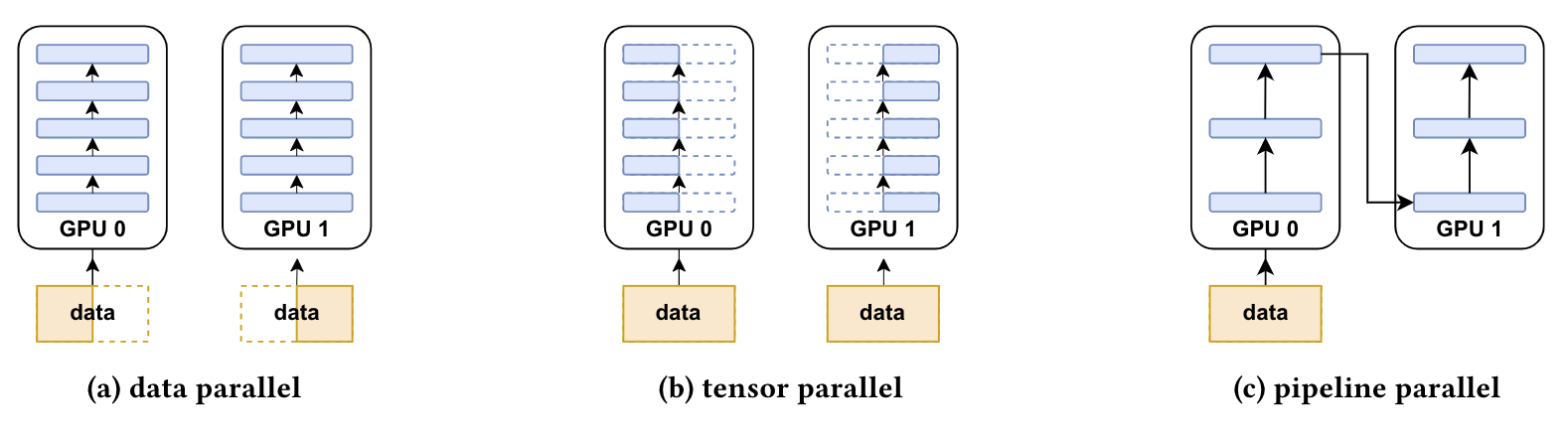
- 数据并行(DataParallel, DP):相同的模型副本被创建多个,每个副本输入数据切片。处理过程并行执行,所有副本在每个训练步骤结束时进行同步
- 张量并行(TensorParallel, TP):每个张量被分割为多个块,避免单个 GPU 存储完整张量,每个张量分片存储在指定 GPU 上。处理时各分片在不同 GPU 上独立并行计算,步骤结束时同步结果。这也被称为水平并行,因为分片在水平维度进行
- 流水线并行(PipelineParallel, PP):模型在垂直方向(层级别)跨多个 GPU 拆分,单个 GPU 仅承载模型的一个或多个层。每个 GPU 并行处理流水线的不同阶段,并对批量数据的小切片进行操作
- 零冗余优化器(Zero Redundancy Optimizer, ZeRO):与 TP 类似也对张量进行分片,但会在正向或反向计算时及时重构完整张量,因此无需修改模型结构。它还支持多种卸载技术以应对 GPU 内存限制
- 分片分布式数据并行(Sharded DDP):这是 ZeRO 核心概念的另一种表述,常见于其他 ZeRO 实现中
1.2、数据并行
即使只有 2 块 GPU 的用户,也能通过简单易用的 PyTorch 内置功能 —— 数据并行(DP)和分布式数据并行(DDP)——享受训练速度的提升。
1.3、ZeRO 数据并行
ZeRO 驱动的数据并行(ZeRO-DP)可通过以下来自该博客文章的示意图说明:
理解起来可能有些困难,但实际上这个概念非常简单。它本质上仍是常规的数据并行(DP),只不过每个 GPU 不再存储完整的模型参数、梯度和优化器状态,而仅存储其中的一个切片。运行时,当某个层需要完整的层参数时,所有 GPU 会同步交换彼此缺失的部分 —— 核心逻辑即是如此。
以一个包含 3 层、每层有 3 个参数的简单模型为例:
1
2
3
4
5
La | Lb | Lc
---|----|---
a0 | b0 | c0
a1 | b1 | c1
a2 | b2 | c2
层 La 的权重为 a0、a1 和 a2。
若我们有 3 块 GPU,分片 DDP(即 Zero-DP)会按如下方式将模型拆分到 3 块 GPU 上:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
GPU0:
La | Lb | Lc
---|----|---
a0 | b0 | c0
GPU1:
La | Lb | Lc
---|----|---
a1 | b1 | c1
GPU2:
La | Lb | Lc
---|----|---
a2 | b2 | c2
从典型 DNN 架构的视角看,这种拆分本质上是与张量并行相同的水平切片(horizontal slicing)。而垂直切片(vertical slicing)则是将完整的层组分配到不同 GPU 上。但这只是起点。
现在,每块 GPU 会像传统 DP 一样接收常规的小批量数据:
1
2
3
x0 => GPU0
x1 => GPU1
x2 => GPU2
输入数据无需修改 —— 它们 “以为” 自己会被常规模型处理。
首先,输入数据进入层 La。
以 GPU0 为例:x0 的前向传播需要 a0、a1、a2 参数,但 GPU0 仅存储 a0 —— 它会从 GPU1 获取 a1,从 GPU2 获取 a2,从而拼接出完整的参数。
同时,GPU1 处理小批量 x1,仅存储 a1,但需要 a0 和 a2,因此从 GPU0 和 GPU2 获取缺失参数。
GPU2 处理输入 x2 时同理:从 GPU0 和 GPU1 获取 a0 和 a1,结合自身的 a2 重构完整张量。
三块 GPU 均重构出完整张量后,前向传播正常执行。
计算完成后,不再需要的数据立即释放——仅在计算时临时使用。重构过程通过预取机制高效完成。
前向传播中,Lb 层、Lc 层按此流程重复;反向传播则按 Lc → Lb → La 的顺序执行。
这让我想到一个高效的团队背包负重分配策略:
- A 携带帐篷
- B 携带炉灶
- C 携带斧头
每晚他们共享彼此的装备,获取自己没有的物品;清晨则打包各自分配的装备继续前行。这就是分片 DDP / Zero-DP 的核心逻辑。
对比之下,若每个人都携带自己的帐篷、炉灶和斧头(即 PyTorch 中的数据并行 DP / DDP),效率会低得多。
阅读相关文献时,你可能会遇到以下同义词:Sharded(分片)、Partitioned(分区)。
仔细观察 ZeRO 对模型权重的划分方式 —— 它与后文将讨论的张量并行(tensor parallelism)非常相似。这是因为它对每个层的权重进行分片/分区,而不同于接下来要讨论的垂直模型并行(vertical model parallelism)。
1.4、朴素模型并行(垂直)与流水线并行
朴素模型并行(Naive Model Parallelism, MP) 指将模型的层组分配到多个 GPU 上的并行方式。其机制相对简单:将目标层通过 .to() 方法迁移到指定设备,此后当数据流入/流出这些层时,自动将数据同步到对应设备,其余层的数据则保持不变。
我们称其为 垂直模型并行(Vertical MP),因为从大多数模型的图示来看,这种并行是沿 “垂直” 方向对层进行切片。例如,假设下图展示一个 8 层模型:
1
2
3
4
=================== ===================
| 0 | 1 | 2 | 3 | | 4 | 5 | 6 | 7 |
=================== ===================
gpu0 gpu1
我们仅需垂直切分为 2 部分,将第 0-3 层放置在 GPU0,第 4-7 层放置在 GPU1。
当数据从第 0 层流向第 1 层、第 1 层流向第 2 层、第 2 层流向第 3 层时,处理过程与常规模型一致。但当数据需要从第 3 层传递到第 4 层时,需从 GPU0 传输到 GPU1,这会引入 通信开销。若参与的GPU位于同一计算节点(如同一物理机),数据拷贝速度较快;但若位于不同计算节点(如多台机器),通信开销可能显著增大。
第 4 层到第 5 层、第 6 层到第 7 层的处理与常规模型一致。当第 7 层计算完成后,通常需要将数据传回第 0 层(假设标签在此处),或反之将标签传输到最后一层。此时才能计算损失并执行优化步骤。
缺陷:
- GPU利用率低:这也是 “朴素” 一词的由来 —— 任何时刻只有一个 GPU 处于工作状态,其余均处于闲置。例如,使用 4 块 GPU 时,其内存容量相当于单卡的 4 倍,但硬件算力未被充分利用。此外,设备间的数据拷贝也会产生额外开销。因此,4 块 6GB 的 GPU 通过朴素 MP 仅能达到与 1 块 24GB GPU 相同的内存容量,但后者训练速度更快(无数据拷贝开销)。当然,若单卡内存为 40GB,需容纳 45GB 的模型时,4 块 40GB 的 GPU 可勉强满足需求(但需考虑梯度和优化器状态的内存占用)
- 共享嵌入层的数据往返拷贝:可能需要在 GPU 间频繁传输共享参数
流水线并行(Pipeline Parallelism, PP) 与朴素 MP 几乎相同,但通过将输入批量划分为 微批量(micro-batches) 并人为构建流水线,解决了 GPU 闲置问题,使不同 GPU 能并发参与计算过程。
以下来自 GPipe 论文的图示中,上半部分为朴素 MP,下半部分为 PP:
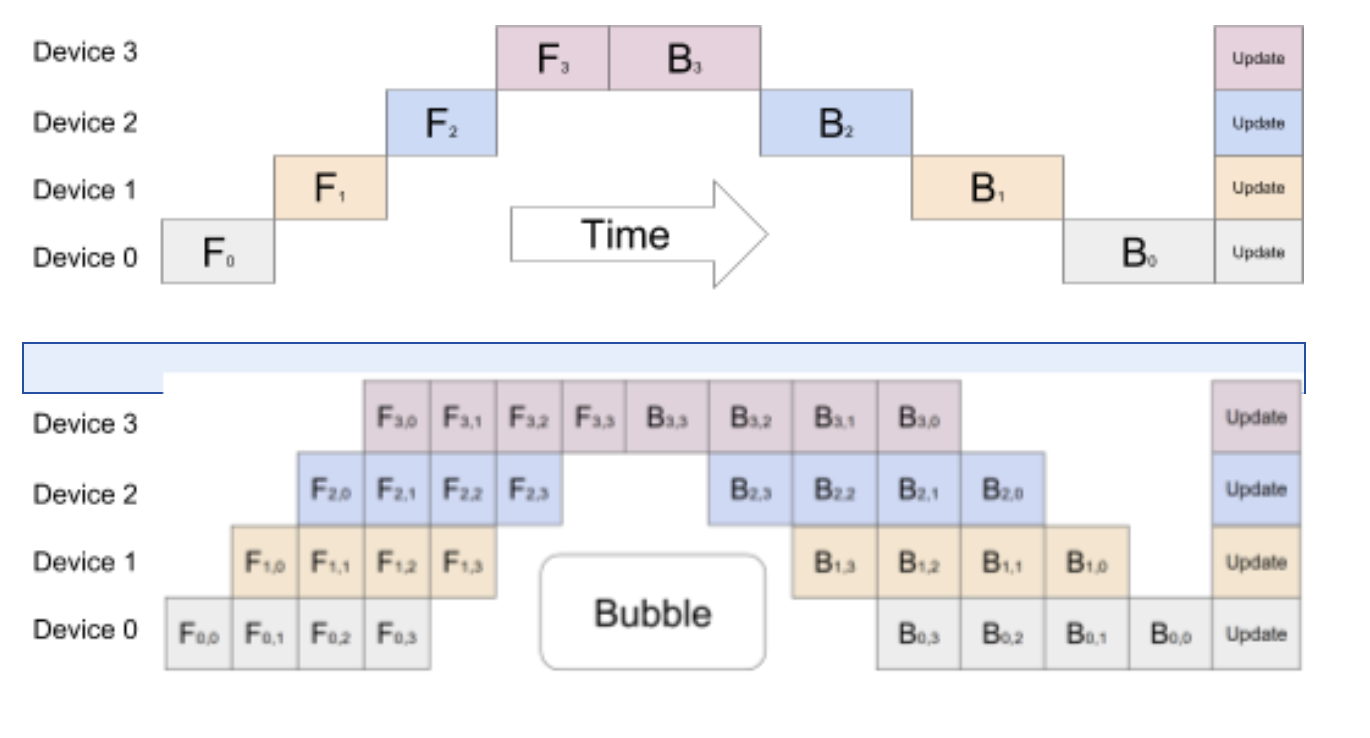
从下方图示不难看出,流水线并行(PP)的 GPU 闲置区域(称为 “气泡”)更少。
图示上下两部分均展示了 4 度并行(即 4 块 GPU 参与流水线):前向路径包含 4 个流水线阶段 F0、F1、F2、F3,反向路径则按 B3、B2、B1、B0 的逆序执行。
PP 引入了一个新的调优超参数 —— 块数(chunks),它定义了同一流水线阶段按顺序处理的数据块数量。例如,下方图示中 chunks=4,GPU0 对块 0、1、2、3 依次执行前向计算(F0,0 至 F0,3),随后等待其他 GPU 完成计算,仅当它们的工作接近完成时,GPU0 才重新开始对块 3、2、1、0 执行反向计算(B0,3 至 B0,0)。
注意,这一概念在本质上等同于梯度累积步骤(Gradient Accumulation Steps, GAS) —— PyTorch 中称为 chunks,而 DeepSpeed 将同一超参数称为 GAS。
由于块数的存在,PP 引入了 微批量(Micro-Batches, MBS) 的概念:数据并行(DP)将全局批量大小划分为小批量,若 DP 度为 4,全局批量大小 1024 会被拆分为 4 个 256 的小批量(1024/4);若块数(或 GAS)为 32,则每个微批量大小为 8(256/32)。每个流水线阶段一次仅处理一个微批量。
计算 DP + PP 组合的全局批量大小时,公式为:$\text{微批量大小} \times \text{块数} \times \text{DP度}$(如 8×32×4=1024)。
回到图示:
- 当
chunks=1时,退化为低效的朴素模型并行(MP) - 当
chunks过大时,微批量尺寸过小,效率同样低下
因此,需通过实验找到使 GPU 利用率最大化的块数值。
尽管图示中存在无法并行化的 “气泡” 闲置时间(最后一个前向阶段需等待反向传播完成流水线),但优化块数值的目标是实现所有参与 GPU 的高并发利用率,从而最小化气泡尺寸。
DeepSpeed、Varuna 和 SageMaker 采用 交错流水线(Interleaved Pipeline) 概念,通过更灵活的调度机制提升并行效率,减少对模型结构的严格依赖。

通过优先执行反向传播,“气泡”(闲置时间)在此方案中进一步减少。
Varuna通过模拟来探索最高效的调度方案,进一步优化了调度策略。
OSLO 基于 Transformers 库实现了流水线并行,无需将模型转换为 nn.Sequential 结构。
1.5、张量并行(Tensor Parallelism)
在张量并行中,每个 GPU 仅处理张量的一个切片,仅在需要完整张量的操作(如聚合)时才拼接完整张量。
本节将采用 Megatron-LM 论文《Efficient Large-Scale Language Model Training on GPU Clusters》中的概念和图示。
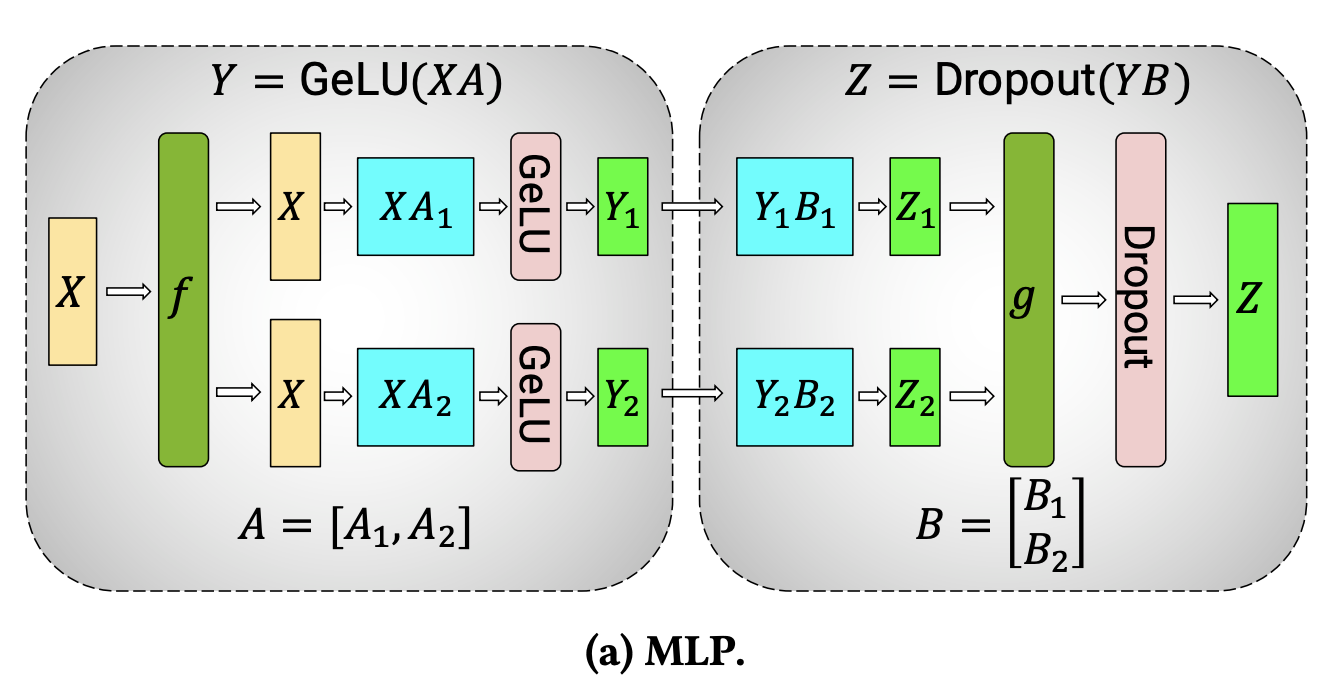
Transformer 的核心组件是一个全连接层nn.Linear,其后接非线性激活函数 GeLU。
沿用 Megatron 论文的符号表示,其点积计算可写为 $Y = \text{GeLU}(XA)$,其中 $X$ 和 $Y$ 是输入/输出向量,$A$ 是权重矩阵。
从矩阵运算的角度观察,很容易理解如何将矩阵乘法拆分到多个 GPU 上:
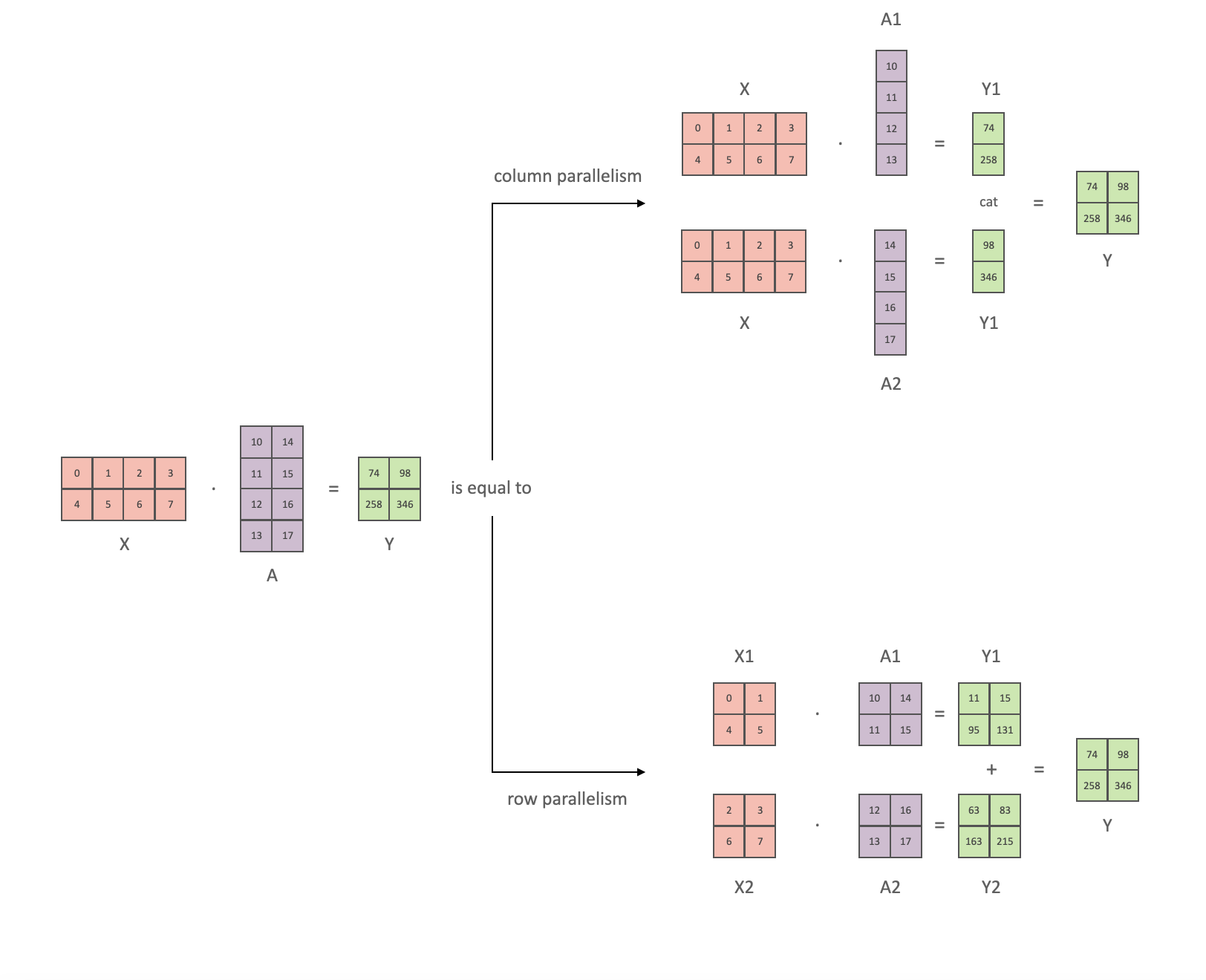
若将权重矩阵 $A$ 按列拆分到 $N$ 个 GPU 上,并并行执行矩阵乘法 $XA_{1}$ 到 $XA_{n}$,最终会得到 $N$ 个输出向量 $Y_{1}, Y_{2}, …, Y_{n}$,这些向量可独立输入 GeLU 激活函数:
利用这一原理,我们可对任意深度的多层感知机(MLP)进行并行化,且无需在 GPU 间同步,直到最后一步才需要从分片重构输出向量。Megatron-LM 论文作者提供了清晰的示意图:
多头注意力层的并行化更为简单,因为其本质上具有并行性 —— 多个注意力头天然独立!
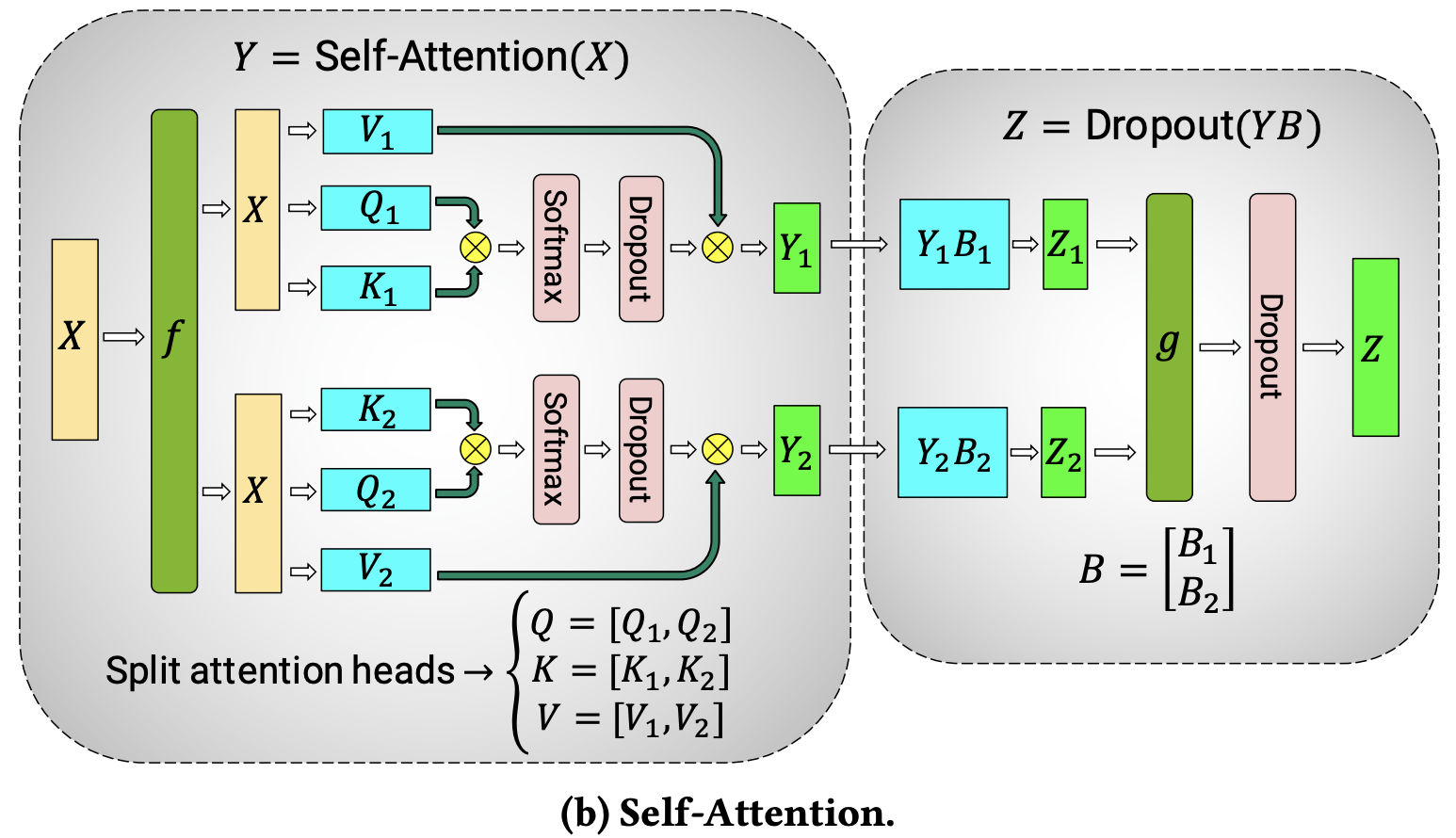
特殊注意事项:张量并行(TP)依赖高速网络,因此不建议跨节点使用。实际中,若单节点有 4 块 GPU,最高张量并行度为 4;若需并行度 8,则需使用至少配备 8 块 GPU 的节点。
本节内容基于 @anton-l 撰写的更详细 TP 概述。
SageMaker 将张量并行与数据并行结合,实现更高效率的处理。
其他名称:DeepSpeed 称其为 张量切片(tensor slicing)。
1.6、DP + PP
以下是 DeepSpeed 流水线教程中的示意图,演示了如何将数据并行(DP)与流水线并行(PP)结合:
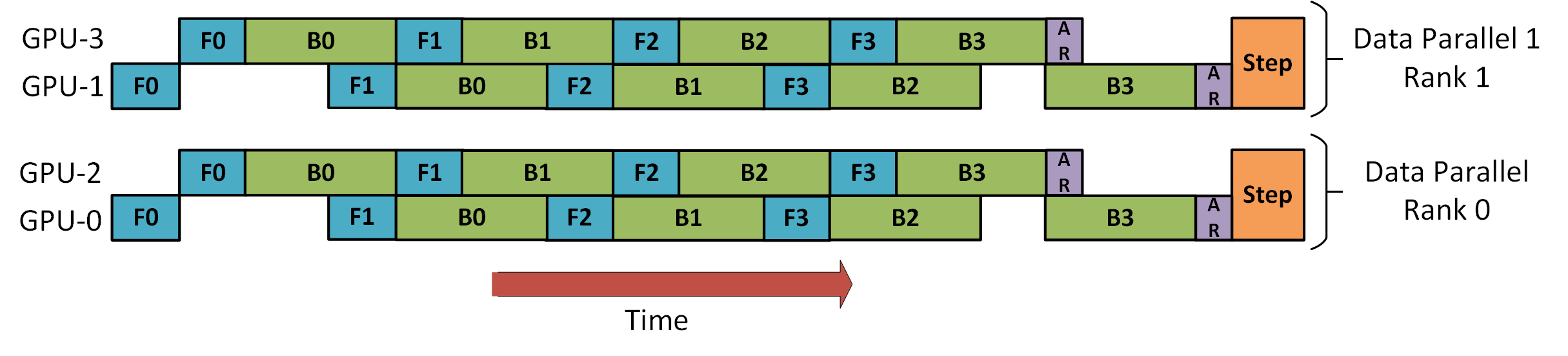
需要注意的是,数据并行中的 rank 0 看不到 GPU2,rank 1 看不到 GPU3。对数据并行而言,系统中仿佛只有 2 个 GPU(GPU0 和 GPU1),它直接向这两个 GPU 输入数据。而 GPU0 通过流水线并行 “秘密” 地将部分负载卸载到 GPU2,GPU1 也通过招募 GPU3 协助实现同样的效果。
由于每个维度至少需要 2 块 GPU,此场景下至少需要 4 块 GPU。
1.7、DP + PP + TP
为实现更高效率的训练,可将流水线并行与张量并行、数据并行结合,形成3D并行,如下图所示:
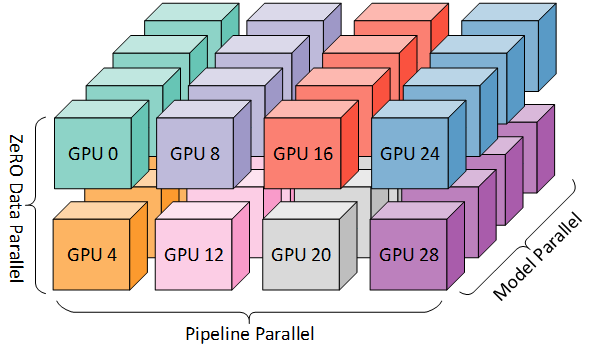
(注:图示来自博客文章《3D并行:扩展至万亿参数模型》,推荐阅读。)
由于每个维度至少需要 2 块 GPU,此场景下至少需要 8 块 GPU。
1.8、ZeRO DP + PP + TP
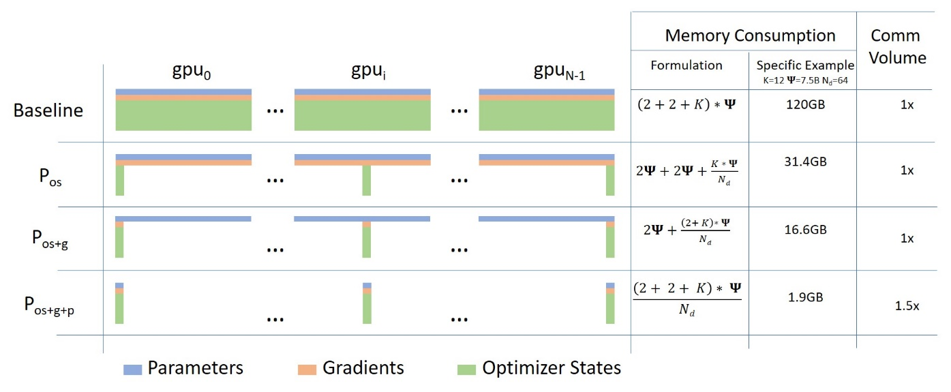
DeepSpeed 的核心特性之一是 ZeRO,它是数据并行的超可扩展版本。ZeRO 通常可独立使用,也可与 PP(流水线并行)、TP(张量并行) 结合。
当 ZeRO-DP 与 PP (可选结合 TP)结合时,通常仅启用 ZeRO 阶段 1(优化器分片)。
理论上,ZeRO 阶段 2(梯度分片)可与流水线并行结合,但会严重影响性能 —— 每个微批次都需要额外的归约-散射(reduce-scatter)操作来聚合梯度,这会引入显著的通信开销。流水线并行的本质是使用小批量数据,并致力于平衡计算强度(微批次大小)与最小化流水线气泡(微批次数量),因此这类通信成本影响极大。
此外,流水线并行已通过分片减少了层数,内存节省效果有限。流水线并行本身会将梯度大小缩减至 1/PP,在此基础上的梯度分片节省效果远不及纯数据并行。
同理,ZeRO 阶段 3 也不适合(需要更多节点间通信)。
ZeRO 的另一优势是 ZeRO-Offload:阶段 1 可将优化器状态卸载到 CPU。
1.9、FlexFlow
FlexFlow 采用了略有不同的并行化方案。
其在 “样本-操作符-属性-参数” 四个维度上实现了 4D 并行:
- 样本(Sample):数据并行(按样本划分)
- 操作符(Operator):将单个操作拆分为多个子操作并行执行
- 属性(Attribute):数据并行(按长度划分)
- 参数(Parameter):模型并行(不区分维度,水平或垂直)
示例:
- 样本并行:假设有 10 个序列长度为 512 的批次,按样本维度划分到 2 个设备,数据形状从 $10 \times 512$ 变为 $5 \times 2 \times 512$
- 操作符并行:以层归一化为例,先计算标准差(std)再计算均值(mean),操作符并行允许两者同时计算。将操作划分到 2 个设备(cuda:0 和 cuda:1),输入数据复制到两设备,cuda:0 计算 std,cuda:1 同时计算 mean
- 属性并行:10 个长度为 512 的批次按属性维度划分到 2 个设备,数据形状变为 $10 \times 2 \times 256$
- 参数并行:类似于张量模型并行或简单的层级模型并行
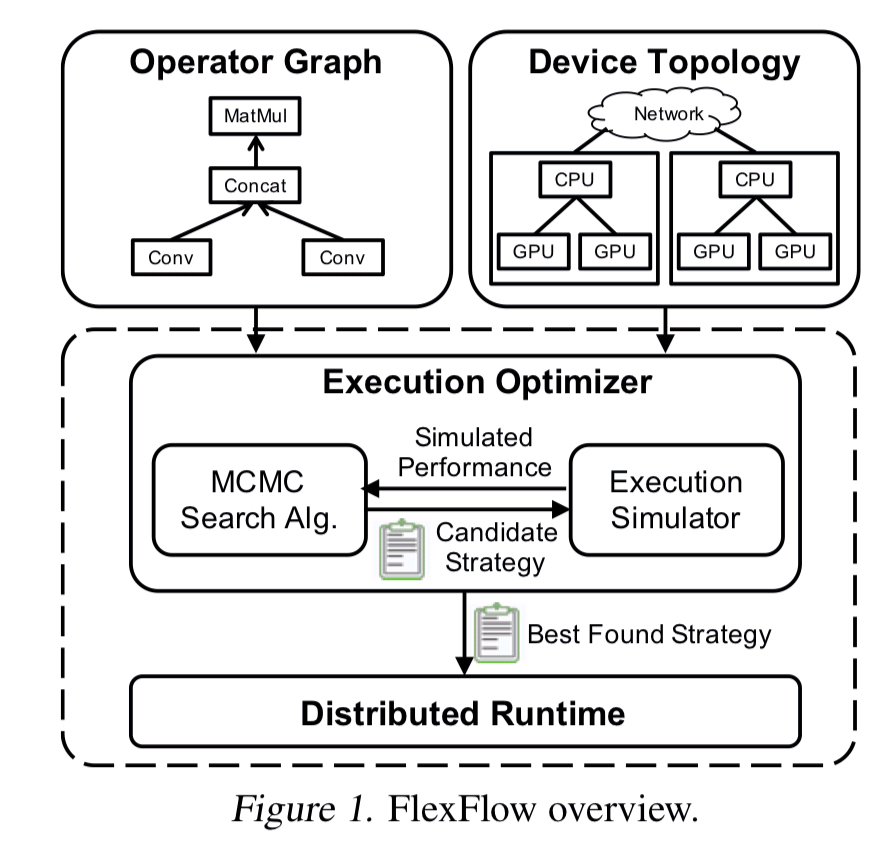
该框架的意义在于,它结合了三类资源:(1)GPU/TPU/CPU,(2)内存/DRAM,(3)高速内部连接/低速外部连接,并通过算法自动优化,决定在何处使用何种并行策略。
一个关键设计是:FlexFlow 专为静态固定工作负载的模型优化 DNN 并行化,因为动态行为模型可能需要在迭代中调整并行策略。
其优势在于:通过在目标集群上运行 30 分钟模拟,生成最适合该环境的并行策略。若添加/移除/更换硬件,它会重新优化策略。不同配置会生成专属优化方案。
1.10、何时选择何种策略
以下是策略选择的大致指南(同类别中排序越前通常效率越高):
⇨ 1.10.1、单 GPU
- 模型可装入单 GPU:
- 常规使用
- 模型无法装入单 GPU:
- ZeRO + 卸载到 CPU(可选 NVMe)
- 上述方案 + 内存中心分块(MCT,若最大层无法装入单 GPU,详见下文)
- 最大层无法装入单 GPU:
- ZeRO - 启用内存中心分块(MCT),通过自动拆分层并顺序执行,支持任意大层。MCT 减少 GPU 上的实时参数数量,但不影响激活内存。当前此需求罕见,需用户手动重写 torch.nn.Linear
⇨ 1.10.2、单节点 / 多 GPU
- 模型可装入单 GPU:
- DDP(分布式数据并行)
- ZeRO(速度取决于具体配置)
- 模型无法装入单 GPU:
- 流水线并行(PP)
- ZeRO
- 张量并行(TP)
- 若节点内有 NVLINK 或 NVSwitch 等高速连接,三者性能相近;若无,PP 快于 TP 或 ZeRO。TP 的并行度也可能影响性能,建议在具体环境中测试
- TP通常限于单节点内使用(TP规模≤单节点GPU数)
- 最大层无法装入单 GPU:
- 未使用 ZeRO 时:必须用 TP(仅 PP 无法解决内存问题)
- 使用 ZeRO 时:参考 “单 GPU” 场景方案
⇨ 1.10.3、多节点 / 多 GPU
- 节点间连接高速:
- ZeRO(几乎无需修改模型)
- PP + TP + DP(通信少,但需大幅修改模型)
- 节点间连接低速且GPU内存紧张:
- DP + PP + TP + ZeRO-1
