本文将阐述 LLM 时代 Embedding 的技术发展脉络,并对 Qwen3 Embedding 和 BGE M3-Embedding 进行系统介绍
1、简述
LLMs 强大的语义理解能力表明,可利用其获取高质量嵌入表示。但与传统仅编码器预训练语言模型(PLMs)类似,仅解码器架构的 LLMs 在原生嵌入空间中面临各向异性挑战 —— 表现为两个词符嵌入的高相似度无法反映其语义相关性。
各向异性 (Anisotropy)
在向量空间中,我们希望不同语义的 token / 句子在各个方向上均匀分布 —— 这叫 “各向同性” (isotropy)。而现实中,经过预训练后的 GPT、BERT 等的向量大多集中在少数几个主导方向上,形成一个狭窄的 “锥体(cone)”。结果就是任意取两条向量,它们的余弦相似度往往很高(0.6、0.7 甚至更高),即使这两条向量对应的 token / 句子语义完全不相干。
为什么会出现各向异性
BERT 的 MLM 或 GPT 的下一词预测会鼓励模型把出现频率高的 token 嵌得更靠近,同时对共现上下文做预测,导致一些高频方向被反复强化。层归一化、残差连接与激活函数也会让表示分布在高维空间里塌缩到一个子空间。缺少显式的“区分或拉开”损失(如对比学习)来迫使不同语义沿不同方向展开。
实际影响
下游需要用余弦距离比较语义相似度(如检索、对齐、聚类)时,直接用 native embedding 会精度很差。需要做额外后处理(中心化 + 白化、对比微调等)或重新训练句向量模型(如 SimCSE、SBERT、FLIP)。
幸运的是,LLMs 的理解与生成能力远超以往的 PLMs,为文本嵌入学习开辟了新机遇,即:
- 作为大规模高质量细粒度文本数据集的数据标注器或生成器;
- 取代当前 PLMs 作为生成更高质量文本嵌入的主干架构。
2、文本 Embedding 历史
2.1、统计机器学习时代
早期研究者主要依赖手动设计的特征表示文本,用于衡量文本间的关联。这类方法需要领域专家精心筛选和设计特征,其效果受限于特征的质量与数量。该方法的发展伴随着输出向量形式的转变:从词袋模型(one-hot向量)到 TF-IDF(稀疏向量),再到文本嵌入(稠密向量)。
随着机器学习技术的进步,研究者开始探索基于统计的文本嵌入学习方法,例如用于信息检索的潜在语义分析(LSA)和用于主题挖掘的潜在狄利克雷分配(LDA)。尽管这些方法能自动学习低维文本嵌入,但仍存在显著缺陷:如 LSA 难以捕捉复杂语义和句法结构,LDA 难以应用于大规模数据集。
2.2、浅层神经网络时代
无监督范式:在词级别,Word2Vec 提出连续词袋模型(CBOW)基于上下文预测中心词,以及跳字模型(Skip-Gram)基于中心词预测上下文。Word2Vec存在两点不足:(a)无法建模全局统计信息;(b)无法处理未登录词(OOV)和词的内部结构,这些缺陷分别被 GloVe 和 FastText 改进。
GloVe 通过预构建全局词共现矩阵充分利用全局信息,证明无需神经网络即可获得高质量词嵌入;FastText 将每个词表示为字符 n-gram 的集合,从而捕捉词的内部结构,助力 OOV 词建模。
有监督范式:句法和语义知识被广泛引入作为监督信号以改进 Word2Vec。例如,DEPS 嵌入将滑动窗口式上下文替换为基于依赖关系的上下文,仅允许修饰词作为目标词的上下文;RCM 和 Paragram 嵌入将 PPDB 和 WordNet 中的语义关系作为约束,使学得的词嵌入能反映这些关系。
2.3、深度神经网络时代
无监督范式:无监督嵌入学习聚焦于无标注数据上的前置任务设计。Skip-Thoughts 采用编码器-解码器架构,对目标句子编码后解码生成相邻句子以学习嵌入;FastSent 从两方面提升 Skip-Thoughts 效率:(a) 使用词嵌入和作为句子嵌入以加速编码;(b) 预测时忽略相邻句子词序以加速训练。Quick-Thoughts 进一步提出判别任务,训练嵌入以从候选句子集中选择与当前句子相邻的句子。
有监督范式:有监督范式下的研究聚焦于寻找特定训练任务与数据,使训练获得的嵌入能有效泛化至其他任务。例如,InferSent 发现 NLI 数据上学习的嵌入在其他下游任务中具有优异迁移性能,而 CoVe 发现神经机器翻译(NMT)学习的词嵌入可良好泛化至其他任务。
多任务范式:GenSen 和 USE 等工作借鉴了各场景的成功实践,将前两类范式中的多任务结合,获得适用于通用任务的句子嵌入。
2.4、预训练语言模型时代
“预训练-微调” 范式下的预训练语言模型(PLMs),其词嵌入被证明集中于高维锥形空间,导致任意两词的相似度计算结果异常高。因此,文本嵌入学习的研究重心转向改善 PLMs 的嵌入空间。
事后优化范式:早期探索聚焦于后处理方法以提升嵌入质量。例如,通过学习流函数或将嵌入空间转换为白化矩阵调整至各向同性空间已被证明有效;此外,对嵌入的若干非理想维度进行标准化也是有效的后处理方法。
无监督与有监督微调范式:在对其他损失函数进行短暂探索后,有监督与无监督范式逐渐统一于对比学习。对比学习针对数据集中每个样本(“锚点”),聚焦构建正负样本,并优化嵌入空间以缩小锚点-正样本距离、扩大锚点-负样本距离。
有监督与无监督场景的差异主要体现在正样本构建方式:
有监督场景中,锚点-正样本对可基于现有标注数据集构建,如检索数据集中的查询-文档对、NLI 数据集中的假设-蕴含对等;
无监督场景中,(a) 同一文本的两个数据增强视图或(b)同一文档中的两个相邻文本被视为锚点-正样本对,增强方式可为字面级(如词删除、反向翻译等)或嵌入级(如 Dropout)。
负样本可通过数据集中随机采样获得,硬负样本挖掘方法可用于发现对嵌入学习更有帮助的挑战性负样本。对比学习的典型损失函数为 InfoNCE,给定锚点样本 $x$、正样本 $x+$ 和负样本集合 \(\{x^{−}_{j}\}^{N}_{j=1}\),记其 $d$ 维嵌入为 $h$、$h+$ 和 \(\{h^{−}_{j}\}^{N}_{j=1}\),则 InfoNCE 损失表示为:
\[\mathcal{L}_{\text{cl}} = -\mathbb{E}_{x\sim D} \log \frac{\exp(s(h, h^+))}{\exp(s(h, h^+)) + \sum_{j=1}^N \exp(s(h, h^-_j))}\]其中 $s: \mathbb{R}^d \times \mathbb{R}^d \to \mathbb{R}$ 为距离函数,$x^+$ 和 \(\{x^{−}_{j}\}^{N}_{j=1}\) 分别为文本 $x$ 的正样本和负样本。基于对比学习的改进聚焦于 损失函数形式 和 正负样本构建方法。
例如,ANCE 探索两阶段训练法:首先利用 BM25 等非嵌入模型方法提取一批负样本用于模型训练,随后用训练好的嵌入模型重新挖掘更高质量负样本以进一步训练模型,该方法已成为训练嵌入模型的标准实践。
受成本限制,真实数据集常存在正样本标注不全的问题 —— 多数数据集中每个查询仅标注约 1 个正样本,这要求在负样本挖掘中谨慎考虑假负例的影响。许多研究者建议从嵌入检索结果中间区域采样或基于相似度分数过滤,可有效提升模型性能。
预训练范式:对比学习在大规模语料上效果显著,但在低数据场景中性能大幅下降。这表明 PLMs 的预训练任务(如 MLM 和 NSP 等)无法使 PLMs 快速适应语义聚合并输出高质量文本嵌入。
因此,部分研究致力于设计更优预训练任务以改善低数据场景下对比学习的性能:
- 早期探索仅使用逆 cloze 任务(ICT)等额外增量预训练任务提升对比学习性能;
- 后续改进涉及模型架构修改,例如 Condenser 利用最后一层
[CLS]隐状态和浅层其他 token 隐状态恢复掩码 token,迫使深层生成的新信息在[CLS]中聚合以重构掩码信息; - SEED-Encoder 和 RetroMAE 将
[CLS]的最终隐状态输入辅助解码器以恢复掩码信息,促进信息在[CLS]处的聚合。
3、作为文本嵌入器的 LLMs
3.1、池化策略
与传统语言模型类似,LLM 内部有一个解码层,用于完成从隐藏状态空间到 token 词汇表空间的映射。几乎所有 LLM 都使用简单的无偏线性层作为解码层。当 LLM 用作文本嵌入器时,嵌入是通过在隐藏状态上的特定池化策略获得的,而不再需要映射到 token 空间。因此,大多数方法直接丢弃解码层,并选择对最后一个 Transformer 层输出的隐藏状态进行池化,以获得每个文本的单个嵌入。
\[[h_{1}^{(L)}, \cdots, h_{n}^{(L)}] = \mathcal{H} = f(x), \quad x \in \mathcal{X}\] \[h = \text{pooling}([h_{1}^{(L)}, \cdots, h_{n}^{(L)}]) = \sum_{i}^{n} \alpha_{i} h_{i}^{L}\]其中,$\mathcal{H}$ 表示通过模型 $f$ 计算得到的隐藏状态。$\alpha_{i}$ 是权重,满足 $\sum_{i}^{n} \alpha_{i} = 1$。
适用于这种情况的四种池化方法是:(加权)平均池化、首位池化、末位池化和部分池化。然而,有些方法并不只是对最后一层的隐藏状态进行加权。例如,有些方法使用可学习模块与最后一层的隐藏状态进行交互(后交互池化),而另一些方法则尝试用其他信息(如注意力权重、隐藏状态等)来增强最终嵌入,这些信息利用了中间层的输出(多层池化)。
(加权)平均池化:平均池化($\alpha_{i} = \frac{1}{n}$)在 BERT 和 T5 中比首位池化表现更好。同时,在基于解码器的 LLM 中,给每个位置分配相同的权重是不合理的,因为由于因果注意力,后面的位置能够看到更多的语义信息。因此,SGPT 建议使用加权平均池化,其直觉是后面的位置应该被赋予更大的权重。
首位池化:首位池化(仅 $\alpha_{1} = 1$)是为具有双向注意力的 PLM 获取嵌入的常用方法。例如,BERT 在输入文本前拼接特殊 token [CLS],[CLS] 位置的嵌入输出将用作整个文本的嵌入。尽管类似 T5 的模型没有像 BERT 中 [CLS] 这样的特殊 token,但 Sentence-T5 使用 T5 编码器输出的第一个嵌入和 T5 解码器输出的 [START] 嵌入作为整个文本的嵌入;然而,这些池化策略的性能略逊于平均池化。对于具有因果注意力的仅解码器 LLM,首位池化不起作用,因为第一个位置的嵌入无法包含后续内容的语义。
末位池化:末位池化(仅 $\alpha_{n} = 1$)是 LLM 时代出现的一种新池化策略。由于因果注意力的单向性,只有最后一个位置显示整个文本的信息。然而,仅解码器 LLM 是通过下一个 token 预测进行预训练的,最后一个位置的嵌入将与潜在的下一个 token 嵌入对齐。如果没有额外的干预,无法保证该嵌入包含整个文本的语义。这里有三种常见的干预措施:
- 基于提示的末位池化:引入特殊提示,诱导模型在最后一个位置总结整个文本的语义。例如,PromptEOL 提出了一个提示模板 “The sentence [X] means in a word:”,其中 [X] 是占位符。在实践中,[X] 被填入输入文本,并使用末位池化策略获取文本嵌入。尽管有许多变体,但这类工作的核心思想是一致的,即将文本嵌入转换为语言建模,并引导模型在最后一个位置总结整个文本的语义
- 特殊token末位池化:一些工作引入特殊 token,如
<EOS>,以在最后一个位置获取嵌入,同时对 LLM 进行增量微调,学习在特殊 token 的位置收敛语义 - 特殊序列末位池化:ChatRetriever 和 DEBATER 在输入文本末尾添加特殊 token 序列,如 [EMB1], · · ·, [EMBt]。作者认为,这些 t 个连续的特殊 token 作为思维链,扩展并引导学习空间以获得更有效的嵌入
部分池化:部分池化($\alpha_{i} = 1$,当 $i$ 大于特定 $k$ 时)也是减轻因果注意力影响的有效方法,这需要基于提示的辅助。Echo 提出一个提示:“Rewrite the sentence:[x], rewritten sentence:[x]”,其中 [x] 是占位符。在实践中,两个占位符都填入相同的文本,并使用平均池化策略获取文本嵌入,但仅在文本第二次出现的范围内进行池化。这样,整个文本已经出现在第一个占位符中,因此填入第二个占位符的每个 token 都可以通过因果注意力访问整个文本信息。
后交互池化:一些工作在传统池化策略之前添加具有注意力机制的复杂模块。NV-Embed 在平均池化之前引入额外的基于注意力的网络,与隐藏状态 H 进行后交互。基于注意力的网络由一个交叉注意力块和一个 MLP 组成,其中交叉注意力中使用的键和值矩阵是可学习的且低秩的,H 被视为查询。
多层池化:一些工作使用后交互模块来混合 LLM 中不同层隐藏状态的信息。例如,提出一种可训练的多层池化方法,使用末位 / 平均池化从多个层聚合文本嵌入。这些嵌入形成一个矩阵 HL,由交叉注意力 Transformer 处理。交叉注意力通过将 HL 与可学习权重矩阵相加来计算,然后导出键和值表示。跨输入使用固定的可学习查询,前馈块的输出用作最终嵌入。
3.2、注意力机制
因果注意力是基于解码器的 LLM 的常见操作,它确保语言建模只能参考前缀来预测下一个 token。然而,大量实证研究表明,因果注意力会降低下游任务的性能。当前方法有:
- 保留因果注意力并使用其他技巧(如特殊池化方法)
- 将其转换为双向注意力并使模型适应它
保持因果注意力:如果模型保持因果注意力,通常需要借助池化技巧来减轻由此产生的负面影响。
转换为双向注意力:考虑到因果注意力是通过 Transformer 中的掩码矩阵实现的,在增量微调期间移除掩码矩阵既方便又快捷。BeLLM 将仅解码器 LLM 中最后几层的因果注意力改为双向注意力。这一尝试的动机是,随着层数的增加,下游任务的性能并不单调提升,而是存在一个转折点。当将仅解码器 LLM 中的因果注意力完全转换为双向注意力时,需要足够的数据或额外的训练任务来使 LLM 适应新的注意力机制。在小规模数据上训练时,仅将最后一层的注意力从因果改为双向可以有效提高在 SemEval 基准上的性能;然而,直接将所有注意力层改为双向会导致性能显著下降。
此外,NV-Embed 表明,当使用足够的数据(数百个数据集)进行增量微调时,LLM 可以自适应地更新参数并完成从因果注意力到双向注意力的转换,而无需额外操作。为了使 LLM 在没有大量训练数据的情况下适应使用双向注意力,LLM2Vec 提出了一种自监督任务,即掩码下一个 token 预测(MNTP)。MNTP 结合了掩码语言建模和下一个 token 预测的思想,其中首先从文本中随机掩码 token,然后使用掩码 token 前一位置的隐藏状态来预测该掩码 token。
动态转换:GirtLM 能够通过多任务学习范式同时处理生成和嵌入任务。因此,GirtLM 可以在保持生成任务的因果注意力的同时,转换为双向注意力以获得高质量的嵌入。
3.3、附加投影器
与在多个隐藏状态上操作的池化策略不同,投影层通常针对单个嵌入执行特定功能。
用于低维嵌入的投影层:根据缩放定律,隐藏层维度(宽度)通常随模型总参数数量增加而增长。例如,T5-11B 的隐藏状态维度为 1024,而主流 70 亿参数的仅解码器 LLM 维度达 4096,均高于 BERT 类模型的 768 维。在实际应用中,高维嵌入会显著增加存储和推理的资源开销,简单的解决方案是在池化后添加投影层 $g: \mathbb{R}^d \to \mathbb{R}^m, m < d $ 以获取低维嵌入。
用于稀疏表示的投影层:与降维目的类似,将文本嵌入转换为稀疏表示可提升模型推理效率,并增强长文档检索等下游任务的表现。
- BERT 类嵌入器方案:通过投影层将文本嵌入映射到词汇表长度的对数几率(logits),再利用门控机制、Top-K 掩码或正则化项实现稀疏化。
- LLM 类嵌入器方案:PromptReps 采用类似 PromptEOL 的提示获取文本嵌入,结合 ReLU 函数、对数饱和和 Top-K 掩码生成文档的稀疏表示。此外,对比学习微调的 LLM 嵌入器经解码层和简单 Top-K 掩码处理后,仍能产出高质量稀疏表示。
3.4、参数高效微调模块
部分研究引入 BitFit 或 LoRA 作为参数高效微调(PEFT)模块,并基于单一数据集进行微调,其核心假设是:小规模数据即可激发 LLM 自身具备的语义泛化能力。另一些研究则采用全参数微调或基于数百个数据集的(多阶段)微调,这种方式足以支持模型参数的大幅更新并避免过拟合。
4、Qwen3 Embedding
Qwen3 嵌入系列提供了一系列模型大小(0.6B、4B、8B),适用于嵌入和重排任务,适应多种部署场景。
基于 Qwen3 基础模型,Embedding 模型和 Reranking 模型分别采用了 双塔结构 和 单塔结构 的设计。通过 LoRA 微调,最大限度地保留并继承了基础模型的文本理解能力。
具体实现如下:
- Embedding 模型接收单段文本作为输入,取模型最后一层[EOS]标记对应的隐藏状态向量,作为输入文本的语义表示;
- Reranking 模型则接收文本对(例如用户查询与候选文档)作为输入,利用单塔结构计算并输出两个文本的相关性得分。
4.1、模型架构
嵌入与重排序模型的核心在于以任务感知的方式评估相关性。给定查询 $q$ 和文档 $d$,这类模型基于指令 $I$ 定义的相似度准则来判断二者的相关性。为使模型具备任务感知的相关性评估能力,训练数据通常组织为 $\{I_{i}, q_{i}, d_{i}^{+}, d_{i, 1}^{-},\cdots, d_{i, n}^{-}\}$,其中 $d_{i}^{+}$ 表示查询 $q_{i}$ 的正例(相关)文档,$d^{-}_{i,j}$ 为负例(不相关)文档。通过在多样化文本对上训练模型,可拓展其在检索、语义文本相似度计算、分类和聚类等一系列下游任务中的适用性。
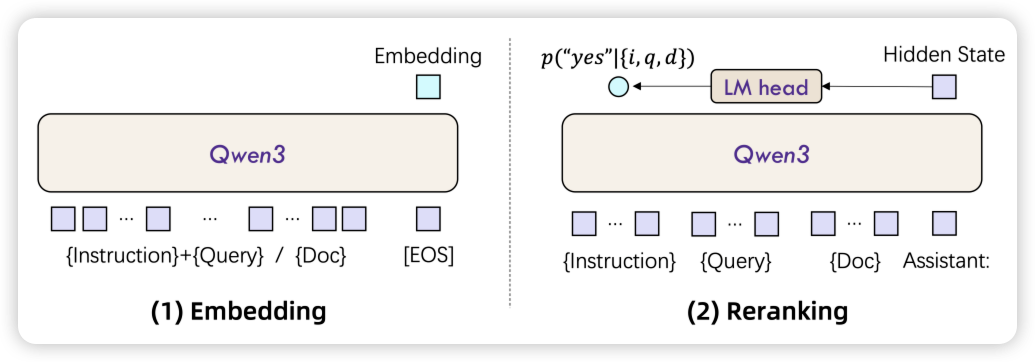
架构设计:Qwen3 嵌入与重排序模型基于 Qwen3 基础模型的稠密版本构建,提供三种规模:0.6B、4B 和 8B 参数。
嵌入模型:对于文本嵌入,采用具有因果注意力机制的 LLM,并在输入序列末尾附加 [EOS] 标记。最终嵌入由最后一层对应 [EOS] 标记的隐藏状态生成。为确保嵌入在下游任务中遵循指令,将指令与查询拼接为单一输入上下文,而文档在输入 LLM 处理前保持不变。查询的输入格式如下:
{Instruction} {Query}<|endoftext|>
重排序模型:为更精准地评估文本相似度,采用大语言模型(LLMs)在单一上下文中执行逐点重排序。与嵌入模型类似,为赋予模型指令遵循能力,将指令纳入输入上下文。具体而言,使用 LLM 聊天模板并将相似度评估任务构造成二分类问题,LLM 的输入遵循如下模板:
<|im_start|>system
Judge whether the Document meets the requirements based on the Query and the
Instruct provided. Note that the answer can only be "yes" or
"no".<|im_end|>
,→
,→
<|im_start|>user
<Instruct>: {Instruction}
<Query>: {Query}
<Document>: {Document}<|im_end|>
<|im_start|>assistant
<think>\n\n</think>\n\n
为基于给定输入计算相关度分数,评估下一个 token 为 “yes” 或 “no” 的概率,数学表达如下:
\[score(q,d)=\frac{e^{P(yes \mid I, q, d)}}{e^{P(yes \mid I, q, d)}+e^{P(no \mid I, q, d)}}\]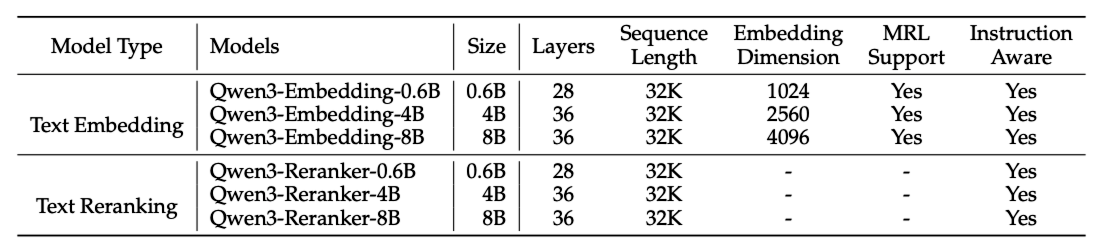
4.2、模型训练
4.2.1、训练目标
对于嵌入模型,采用了一种基于 InfoNCE 框架的改进对比损失。给定一个包含 $N$ 个训练实例的批次,损失定义为:
\[L_{\text{embedding}}=-\frac{1}{N}\sum_{i}^{N}\log\frac{e^{\left(s\left(q_{i}, d_{i}^{+}\right)/\tau\right)}}{Z_{i}} \tag{1}\]其中 $s(\cdot,\cdot)$ 是相似性函数(使用余弦相似性),$\tau$ 是温度参数,$Z_{i}$ 是归一化因子,用于聚合正样本对与各种负样本对的相似性得分:
\[Z_{i}=e^{\left(s\left(q_{i}, d_{i}^{+}\right)/\tau\right)}+\sum_{k}^{K} m_{i k} e^{\left(s\left(q_{i}, d_{i, k}^{-}\right)/\tau\right)}+\sum_{j \neq i} m_{i j} e^{\left(s\left(q_{i}, q_{j}\right)/\tau\right)}+\sum_{j \neq i} m_{i j} e^{\left(s\left(d_{i}^{+}, d_{j}\right)/\tau\right)}+\sum_{j \neq i} m_{i j} e^{\left(s\left(q_{i}, d_{j}\right)/\tau\right)}\]其中这些项表示与以下内容的相似性:
- 正样本文档 $d_{i}^{+}$
- $K$ 个难负样本 $d_{i, k^{\prime}}^{-}$
- 批次中的其他查询 $q_{j}$
- 批次中的其他文档 $d_{j}$ 与正样本文档 $d_{i}^{+}$ 的比较
- 批次中的其他文档 $d_{j}$ 与查询 $q_{i}$ 的比较
掩码因子 $m_{i j}$ 旨在减轻假阴性的影响,其定义为:
\[m_{i j}=\left\{\begin{array}{ll} & 0 \ \text{if } s_{i j}>s\left(q_i, d_i^{+}\right)+0.1 \text{ 或 } d_j==d_i^{+}, \\ & 1 \ \text{otherwise}, \end{array}\right.\]其中 $s_{i j}$ 是 $q_{i}, d_{j}$ 或 $q_{i}, q_{j}$ 的对应得分。
对于重排序模型,优化了定义为以下形式的监督微调(SFT)损失:
\[L_{\text{reranking}}=-\log p(l\mid\mathcal{P}(q, d)) \tag{2}\]其中 $p(\cdot\mid*)$ 表示由 LLM 分配的概率。标签 $l$ 对于正样本文档为 “是”,对于负样本为 “否”。该损失函数鼓励模型为正确标签分配更高的概率,从而提高排序性能。
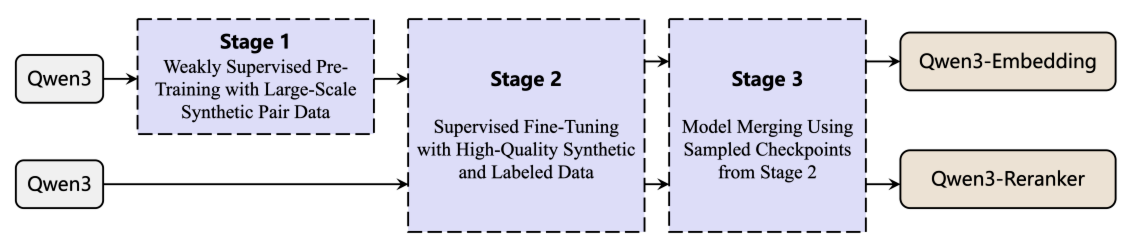
4.2.2、多阶段训练
多阶段训练是训练文本嵌入模型的常用方法。该策略通常始于在包含噪声的大规模半监督数据上进行初始训练,随后使用较小规模的高质量监督数据集进行微调。
这种两步流程可提升嵌入模型的性能和泛化能力:大规模弱监督训练数据对模型的泛化能力贡献显著,而后续阶段通过高质量数据微调可进一步改善模型表现。嵌入模型的两个训练阶段均采用公式1定义的优化目标,而重排序模型训练则使用公式2定义的损失函数作为优化目标。
Qwen3 嵌入系列在现有多阶段训练框架基础上引入以下关键创新:
- 通过超大规模弱监督数据进行对比学习预训练:不同于以往工作(如GTE、E5、BGE模型)从问答论坛或学术论文等开源社区收集弱监督训练数据,Qwen3 提出利用基础模型的文本理解与生成能力直接合成配对数据。该方法可在合成提示中任意定义配对数据的任务、语言、长度、难度等多维度属性。与开放域数据收集相比,基础模型驱动的数据合成具有更强的可控性,尤其在低资源场景和语言中可精确管理生成数据的质量与多样性
- 基于高质量标注数据进行监督训练:由于 Qwen3 基础模型的卓越性能,合成数据具有显著的高质量特性。因此,在第二阶段监督训练中选择性融入此类高质量合成数据,可进一步提升模型整体性能与泛化能力
- 模型融合:受前人工作启发,在完成监督微调后,Qwen3 应用基于球面线性插值(slerp)的模型融合技术,将微调过程中保存的多个模型检查点进行合并。该步骤旨在增强模型在不同数据分布下的鲁棒性与泛化性能
需注意的是,重排序模型的训练流程不包含第一阶段的弱监督训练环节。
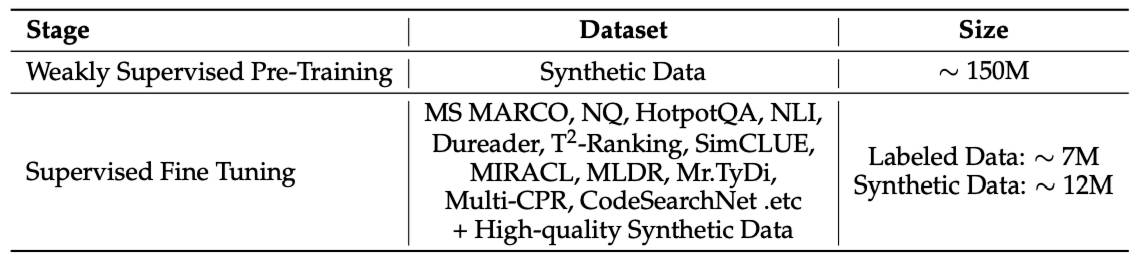
4.2.3、合成数据集
为构建用于训练各类相似度任务模型的鲁棒合成数据集,生成了涵盖检索、双文本挖掘、分类和语义文本相似度(STS)等类别的多样化文本对。这些合成数据对的质量通过使用 Qwen3-32B 模型作为数据合成的基础模型来保障。
Qwen3 设计了多样化的提示策略,以提升生成数据的多样性和真实性。例如,在文本检索任务中,利用 Qwen3 的多语言预训练语料库合成数据。在数据合成过程中,为每个文档分配特定角色以模拟用户对该文档的潜在查询,这种用户视角的注入增强了合成查询的多样性和真实性。
具体而言,使用检索模型从角色库中为每个文档识别前五名角色候选,并将这些文档及其角色候选呈现给提示词,引导模型输出最适合查询生成的角色配置。此外,提示词还融入了查询类型(如关键词、事实型、摘要型、判断型)、查询长度、难度和语言等多维度属性,这种多维方法确保了合成数据的质量和多样性。
最终,共创建了约 1.5亿 对多任务弱监督训练数据。实验表明,使用这些合成数据训练的嵌入模型在下游评估中表现优异,尤其在 MTEB 多语言基准测试中超越了许多先前的监督模型。这促使 Qwen3 对合成数据进行筛选,以识别高质量数据对用于第二阶段的监督训练。Qwen3 采用简单的余弦相似度计算来选择数据对,从随机采样数据中保留余弦相似度大于 0.7 的样本,最终筛选出约 1200万 对高质量监督训练数据用于进一步训练。
以下是合成检索文本对的示例。检索数据通过 “文档到查询” 的方式合成:从 Qwen3 基础模型的预训练语料库中收集多语言语料作为文档来源,然后应用两阶段生成流程,包括:
- 配置阶段
- 查询生成阶段
在配置阶段,使用 LLMs 确定合成查询的 “问题类型”、“难度” 和 “角色”。角色候选从 Persona Hub 中检索,选择与给定文档最相关的前五名,该步骤旨在增强生成查询的多样性。使用的模板如下:
给定一篇 **段落(Passage)** 和 **角色(Character)**,从三个字段 “角色、问题类型、难度” 中选择合适选项,并以 JSON 格式返回输出。
首先,从候选角色中选择可能对该段落感兴趣的 **角色**;然后选择该角色可能针对段落提出的 **问题类型(Question_Type)**;最后根据段落内容、角色和问题类型,选择可能问题的 **难度(Difficulty)**。
**角色**:由输入的 **Character** 给出
**问题类型**:
- keywords(关键词型):...
- acquire_knowledge(知识获取型):...
- summary(摘要型):...
- yes_or_no(是非型):...
- background(背景型):...
**难度**:
- high_school(高中水平):...
- university(大学水平):...
- phd(博士水平):...
以下是示例:
<Example1> <Example2> <Example3>
现在,根据用户提供的 **段落** 和 **角色** 生成 **输出**,其中 **段落** 为{language}语言,**角色** 为英文。
请确保仅生成内容为英文的 JSON 输出。
**段落(Passage)**:
{passage}
**角色(Character)**:
{character}
在查询生成阶段,使用第一阶段选定的配置来指导查询生成。此外,会显式指定生成查询的预期长度和语言。使用的模板如下:
给定**角色(Character)**、**段落(Passage)** 和 **需求(Requirement)**,从角色视角生成符合需求且可用于检索该段落的查询,请以 JSON 格式返回结果。
**示例**:
<example>
现在,根据用户提供的 **角色**、**段落** 和 **需求** 生成 **输出**,其中 **段落** 为 {corpus_language} 语言,**角色** 和 **需求** 为英文。
请确保仅生成 JSON 输出,键为英文,值为 {queries_language} 语言。
**角色(Character)**
{character}
**段落(Passage)**
{passage}
**需求(Requirement)**
- 类型(Type):{type};
- 难度(Difficulty):{difficulty};
- 长度(Length):生成句子的长度应为{length}个单词;
- 语言(Language):生成结果的语言应为{language}语言
5、M3-Embedding
M3-Embedding 采用了如下技术方案:
- 自知识蒸馏框架: 联合学习多种检索功能([CLS] 嵌入用于密集检索,其他标记嵌入用于稀疏和多向量检索),基于集成学习原理整合不同检索功能的相关度分数作为教师信号,通过知识蒸馏增强学习过程。
- 优化批处理策略: 实现大批量、高训练吞吐量,提升嵌入判别能力。
- 高质量数据整理: 数据集来源包括从多语言语料库提取无监督数据、整合有监督数据、合成稀缺训练数据,三者互补并应用于不同训练阶段,为文本嵌入奠定基础。
5.1、数据整理
BCE 从三个来源进行全面的数据收集:
- 未标记语料库中提取无监督数据
- 无监督数据的整理方式是从多种多语言语料库中提取富含语义结构的内容,例如
标题-正文、标题-摘要、指令-输出等 - 最终引入了 194 种语言的 12 亿文本对和 2655 组跨语言对应关系
- 无监督数据的整理方式是从多种多语言语料库中提取富含语义结构的内容,例如
对于长文本(例如新闻),开头的句子往往是总结性陈述,模型可以仅依赖这些初始句子中呈现的信息来建立相关关系。为了防止模型仅关注这些开头句子,M3 实施了一种随机打乱整个文本内段落顺序的策略。
具体来说,将文本分为三个部分,随机打乱它们的顺序,然后重新组合。这种方法允许相关文本段在长序列内的任何位置随机出现。在训练过程中,对段落以 0.2% 的概率应用这一操作。
- 标记语料库中获取微调数据
- 从标记语料库中收集了相对较小但多样化的高质量微调数据
- 通过合成生成微调数据
- 生成合成数据以缓解长文档检索任务的短缺问题
- 从维基百科、悟道和 mC4 数据集中采样长文章,并从中随机选择段落,然后使用 GPT-3.5 基于这些段落生成问题。生成的问题和采样的文章构成新的文本对,加入微调数据中
给 GPT3.5 的提示是:“你是一个充满好奇心的人工智能助手,请根据以下文本生成一个具体且有价值的问题。生成的问题应围绕该文本的核心内容,避免使用代词(如‘this’)。注意你只需生成一个问题,不包含额外内容:”。
5.2、混合检索
M3-Embedding 统一了嵌入模型的常见检索功能,即密集检索、词汇(稀疏)检索和多向量检索:
密集检索:输入查询文本 $q$ 通过文本编码器转换为隐藏状态 $H_{q}$,使用特殊标记 “[CLS]” 的归一化隐藏状态作为查询表示:
同理,段落 $p$ 的嵌入表示为:
\[e_p = \text{norm}(H_p[0])\]查询与段落的相关度分数通过两者嵌入向量的内积计算:
\[s_{\text{dense}} \leftarrow \langle e_p, e_q \rangle\]词汇检索:输出嵌入还用于评估每个词项的重要性,以支持词汇检索。对于查询中的每个词项 $t$(词项对应标记 token),词项权重计算为:
\[w_{qt} \leftarrow \text{Relu}(W_{\text{lex}}^T H_q[i])\]其中$W_{\text{lex}} \in \mathbb{R}^{d \times 1}$是将隐藏状态映射为浮点数的矩阵。若词项 $t$ 在查询中多次出现,仅保留最大权重。段落中词项权重的计算方式相同。基于词项权重估计,查询与段落的相关度分数由两者共现词项的联合重要性决定(记为\(q \cap p\)):
\[s_{\text{lex}} \leftarrow \sum_{t \in q \cap p} (w_{qt} * w_{pt})\]多向量检索:作为密集检索的扩展,多向量方法利用全部输出嵌入表示查询和段落:
\[E_q = \text{norm}(W_{\text{mul}}^T H_q), \quad E_p = \text{norm}(W_{\text{mul}}^T H_p)\]其中 $W_{\text{mul}} \in \mathbb{R}^{d \times d}$ 是可学习的投影矩阵。遵循 ColBert 的方法,使用后期交互计算细粒度相关度分数:
\[s_{\text{mul}} \leftarrow \frac{1}{N} \sum_{i=1}^N \max_{j=1}^M E_q[i] \cdot E_p^T[j]\]其中 $N$ 和 $M$ 分别为查询和段落的长度。
得益于嵌入模型的多功能性,检索过程可通过混合方式执行:
- 各检索方法独立获取候选结果(多向量方法因计算成本高可跳过此步骤)
- 最终检索结果基于集成相关度分数重新排序:
\(s_{\text{rank}} \leftarrow w_1 \cdot s_{\text{dense}} + w_2 \cdot s_{\text{lex}} + w_3 \cdot s_{\text{mul}}\)
其中 $w_1$、$w_2$、$w_3$ 的值由下游场景决定。
5.3、自知识蒸馏
嵌入模型的训练目标是区分正样本与负样本。训练过程通过最小化 InfoNCE 损失实现,其一般形式由以下损失函数表示:
\[L_s(\cdot) = -\log \frac{\exp(s(q, p^*) / \tau)}{\sum_{p \in \{p^*, P'\}} \exp(s(q, p) / \tau)}\]其中,$p^*$ 和 $P’$ 分别表示查询 $q$ 的正样本和负样本;$s(\cdot)$ 为 ${s_{\text{dense}}(\cdot), s_{\text{lex}}(\cdot), s_{\text{mul}}(\cdot)}$ 中的任意函数。
不同检索方法的训练目标可能相互冲突,因此原生多目标训练可能不利于嵌入质量。为优化多种检索功能,M3 提出在自知识蒸馏框架下统一训练过程。
基于集成学习原理,不同检索方法的预测结果因其异构性可整合为更准确的相关度分数。最简单的整合形式为不同预测分数的加权和:
\[s_{\text{inter}} \leftarrow w_1 \cdot s_{\text{dense}} + w_2 \cdot s_{\text{lex}} + w_3 \cdot s_{\text{mul}}\]随后计算 $L_{\text{dense}}$、$L_{\text{lex}}$、$L_{\text{mul}}$ 和 $L_{\text{inter}}$ 的加权和作为无自知识蒸馏的损失函数:
\[L \leftarrow \frac{\lambda_1 \cdot L_{\text{dense}} + \lambda_2 \cdot L_{\text{lex}} + \lambda_3 \cdot L_{\text{mul}} + L_{\text{inter}}}{4}\]嵌入模型的训练质量可通过知识蒸馏提升,其技术利用另一排序模型的细粒度软标签。M3 直接将整合分数 $s_{\text{inter}}$ 作为 teacher 信号,将各检索方法的损失函数修改为:
\[L'_* \leftarrow -p(s_{\text{inter}}) \cdot \log p(s_*)\]其中 $p(\cdot)$ 为 softmax 激活函数,$s_*$ 为 $s_{\text{dense}}$、$s_{\text{lex}}$ 和 $s_{\text{mul}}$ 中的任意一种。进一步整合并归一化修改后的损失函数:
\[L' \leftarrow \frac{\lambda_1 \cdot L'_{\text{dense}} + \lambda_2 \cdot L'_{\text{lex}} + \lambda_3 \cdot L'_{\text{mul}}}{3}\]最终,自知识蒸馏的损失函数通过 $L$ 和 $L’$ 的线性组合得到:
\[L_{\text{final}} \leftarrow \frac{L + L'}{2}\]训练过程包含多阶段工作流:
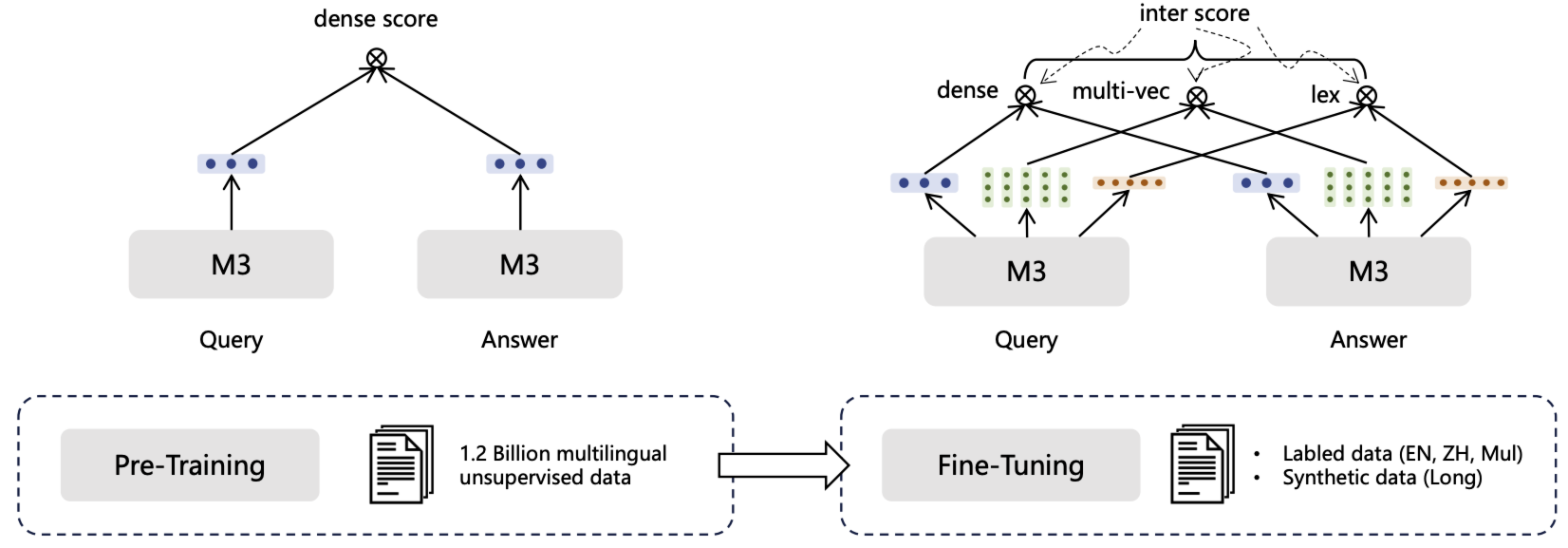
- 第一阶段:使用海量无监督数据预训练文本编码器(基于 RetroMAE 方法适配的 XLM-RoBERTa 模型),仅以对比学习的基本形式训练密集检索功能
- 第二阶段:应用自知识蒸馏微调嵌入模型,以建立三种检索功能。由于 $W_{\text{lex}}$ 的随机初始化会导致训练初期 $s_{\text{lex}}$ 准确率低、$L_{\text{lex}}$ 高,因此训练过程中设置 $w_1=1$,$w_2=0.3$,$w_3=1$,$\lambda_1=1$,$\lambda_2=0.1$,$\lambda_3=1$。该阶段同时使用标记数据和合成数据,并按 ANCE 方法为每个查询引入硬负样本
ANCE - APPROXIMATE NEAREST NEIGHBOR NEGATIVE CONTRASTIVE LEARNING FOR DENSE TEXT RETRIEVAL
密集检索(DR)的一个关键挑战是在其表示学习期间构建适当的负样本,不同于重排中负样本自然是来自之前检索阶段的不相关文档,在第一阶段检索中,DR模型必须区分整个语料库中的相关文档与所有不相关的文档。
在密集检索中常见条件下,局部批内负样本会导致梯度范数减小,从而导致随机梯度方差高和训练收敛缓慢 —— 局部负采样是密集检索效果不佳的瓶颈。
梯度范数较大的负样本更可能大幅降低训练损失,而梯度趋于零的样本则无信息价值。损失趋近于零的负样本梯度也趋近于零,对模型收敛贡献极小。密集检索模型训练的收敛性依赖于构造负样本的信息性。
受文本检索两个常见特性影响,批量内局部负样本难以提供有效样本:
设 $D^{-*}$ 为与 $D^+$ 难以区分的信息性负样本集合,$b$ 为批量大小,则:
(1)$b \ll \mid C \mid$(批量大小远小于语料库规模);
(2)$\mid D^{-*} \mid \ll \mid C \mid$(仅少数负样本具信息性,语料库多数样本完全不相关)。
两者共同导致随机小批量包含有意义负样本的概率 $p = \frac{b \mid D^{-*} \mid}{\mid C \mid ^2}$ 趋近于零。因此,从局部训练批量中选择负样本难以为密集检索提供最优训练信号。
分析表明,从语料库全局构建负样本即便并非必需,也具有重要意义。所以,近似最近邻负对比估计(ANCE) 通过异步更新的 ANN 索引从整个语料库中选择负样本。
ANCE 从 ANN 索引中通过 DR 模型检索到的顶部文档中采样负样本,优化目标为:
\[\theta^* = \underset{\theta}{\arg\min} \sum_q \sum_{d^+ \in D^+} \sum_{d^- \in D^-_{\text{ANCE}}} l(f(q, d^+), f(q, d^-))\]其中 \(D^-_{\text{ANCE}} = \text{ANN}_f(q,d) \setminus D^+\),$\text{ANN}_f(q,d)$ 表示通过 $f()$ 从 ANN 索引中检索到的顶部文档。
根据定义,\(D^-_{\text{ANCE}}\) 是当前 DR 模型的最难负样本,即 \(D^-_{\text{ANCE}} \approx D^{-*}\)。从理论上讲,这些信息更丰富的负样本具有更高的训练损失和梯度范数上界,能够提升训练收敛性。
在随机训练过程中,DR 模型 $f()$ 每批次更新一次。维护最新的 ANN 索引以选择新的 ANCE 负样本颇具挑战性,因为索引更新需要两个操作:
1)推理:使用更新后的 DR 模型刷新语料库中所有文档的表示;
2)建索引:使用更新后的表示重建 ANN 索引。
尽管建索引过程效率较高,但每批次执行推理的计算成本过高 —— 需对整个语料库进行前向传播,而语料库规模远大于训练批次。
因此,ANCE 实现了异步索引刷新机制,每 $m$ 个批次更新一次 ANN 索引(即使用检查点 $f_k$)。如图所示,除训练器外,运行一个推理器,其获取最新检查点(如 $f_k$)并重新计算整个语料库的编码。
同时,训练器继续使用来自 \(\text{ANN}_{f_{k-1}}\) 的 \(D^-_{f_{k-1}}\) 进行随机学习。一旦语料库重新编码完成,推理器将更新 ANN 索引($\text{ANN}_{f_k}$)并提供给训练器。
在此过程中,ANCE 负样本($D^-_{\text{ANCE}}$)通过异步更新来 “追赶” 随机训练进程。ANN 索引与 DR 模型优化之间的差距取决于训练器与推理器之间的计算资源分配。1:1 的 GPU 资源分配足以最小化该差距的影响。
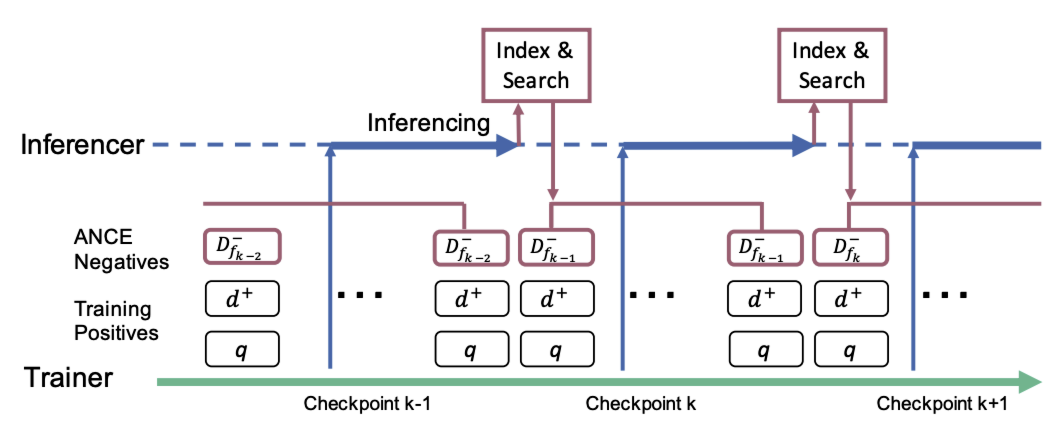
ANCE 异步训练机制:训练器(Trainer)利用 ANN 索引中的负样本学习表示;推理器(Inferencer)通过近期检查点更新语料库中文档的表示,一旦完成,便使用最新编码刷新 ANN 索引
5.4、高效批处理
嵌入模型需从多样且海量的多语言数据中学习,以全面捕捉不同语言的通用语义,同时需保持尽可能大的批量大小(引入大量批内负样本),以确保文本嵌入的判别能力。鉴于 GPU 内存和计算能力的限制,传统方法通常将输入数据截断为短序列,以实现高训练吞吐量和大批量训练。
然而,这种常规做法对 M3-Embedding 并不适用 —— 因其需同时从短序列和长序列数据中学习,以有效处理不同粒度的输入。M3 通过优化批处理策略提升训练效率,实现了高训练吞吐量和大批量训练。
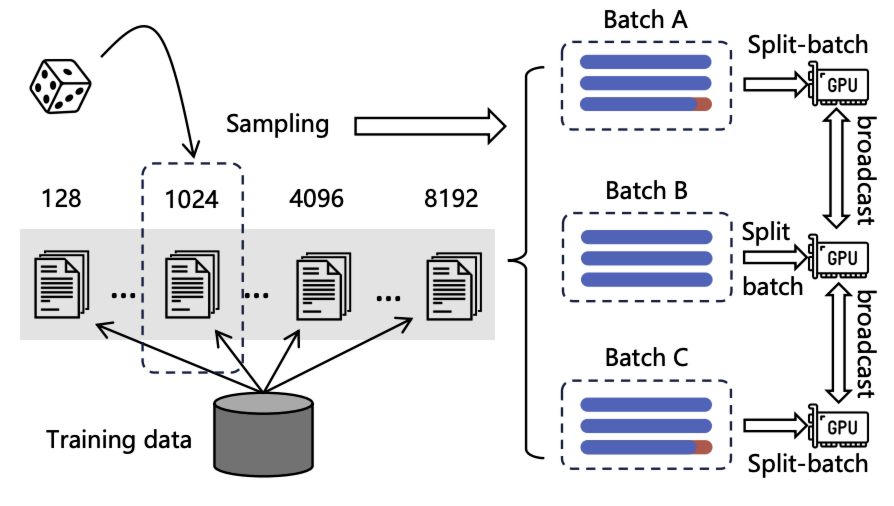
-
按序列长度分组预处理
训练数据按序列长度分组,生成小批量(mini-batch)时从同一组中采样。由于序列长度相近,该策略显著减少了序列填充(图中红色标记部分),促进 GPU 资源的高效利用。 -
固定随机种子实现负载均衡
为不同 GPU 采样训练数据时,始终固定随机种子,确保各设备负载均衡,并最小化每个训练步骤的等待时间。 -
长序列数据的子批次分割
处理长序列训练数据时,将 mini-batch 进一步划分为子批次,以降低内存占用。通过梯度检查点迭代编码每个子批次,并收集所有生成的嵌入向量。该方法可显著增大批量大小:例如,处理长度为 8192 的文本时,批量大小可提升 20 倍以上。 -
分布式环境下的嵌入广播
不同 GPU 生成的嵌入向量通过广播机制共享,使每个设备在分布式环境中获取所有嵌入,大幅扩展批内负样本的规模。
针对计算资源或数据资源严重受限的用户,M3 提出更简单的 MCLS 方法:推理时在长文档中插入多个 CLS 标记,将所有 CLS 嵌入的平均值作为文档的最终嵌入。该方法虽简单,实际效果却十分显著。
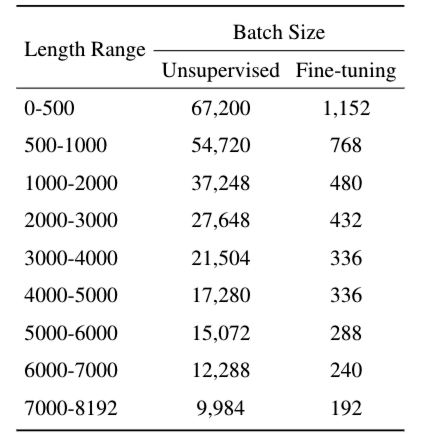
以下是对文本中超参数信息的总结,采用表格形式呈现,便于清晰查看各阶段的关键参数设置:
5.5、超参数
预训练阶段超参数:
| 参数类型 | 具体设置 |
|---|---|
| 查询最大长度 | 512 |
| 段落最大长度 | 8192 |
| 学习率 | 5×10⁻⁵ |
| 预热比率(Warmup Ratio) | 0.1 |
| 权重衰减(Weight Decay) | 0.01 |
| 训练步数 | 25,000 步 |
| GPU配置 | 96 个 A800(80GB) GPU,不同序列长度范围使用不同批量大小 |
微调阶段超参数:
| 参数类型 | 具体设置 |
|---|---|
| 负样本采样数 | 每个查询采样 7 个负样本 |
| 批量大小 | 参见下表 |
| 预热阶段 | 约 6000 步,对密集嵌入、稀疏嵌入和多向量进行预热 |
| 训练方法 | 自知识蒸馏统一训练 |
| GPU配置 | 24 个 A800(80GB) GPU |
参考文献
- When Text Embedding Meets Large Language Model: A Comprehensive Survey
- Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
- M3-Embedding: Multi-Linguality, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation
- Qwen3 Embedding:新一代文本表征与排序模型
- APPROXIMATE NEAREST NEIGHBOR NEGATIVE CONTRASTIVE LEARNING FOR DENSE TEXT RETRIEVAL
